Mamoda2.5快速摘要:
Mamoda2.5是字节跳动Mamoda Team研发的统一多模态生成模型,支持视频生成、图像编辑与视频编辑,适用于AIGC内容创作与多模态工作流。
- 模型名称:Mamoda2.5,部分资料中也写作MammothModa2.5。
- 开发公司:ByteDance Mamoda Team。
- 发布时间:2026年5月4日公开论文与项目主页,据2026年5月官方发布。
- 主要功能:支持文生图、文生视频、图像编辑、视频编辑与多模态理解。
- 技术架构:采用Qwen3-VL-8B理解模块与DiT-MoE生成架构,包含128个专家与Top-8路由机制。
- 参数规模:总参数约25B,单次推理激活约3B参数,据官方技术报告显示。
- 推理速度:720p 93帧视频生成约110秒,据官方测试相比Wan2.2 A14B快12倍以上。
- 视频编辑:4步蒸馏模型延迟约9.2秒,据OpenVE-Bench与FiVE-Bench测试排名第一。
- 开源情况:采用Apache-2.0协议,支持商业使用,据项目主页显示。
- 使用要求:目前主要面向研究与开发者,完整官方API尚未正式开放。
- 适用场景:AI短片生成、视频字幕自动生成、广告视频编辑、会议记录AI工具与多语言内容制作。
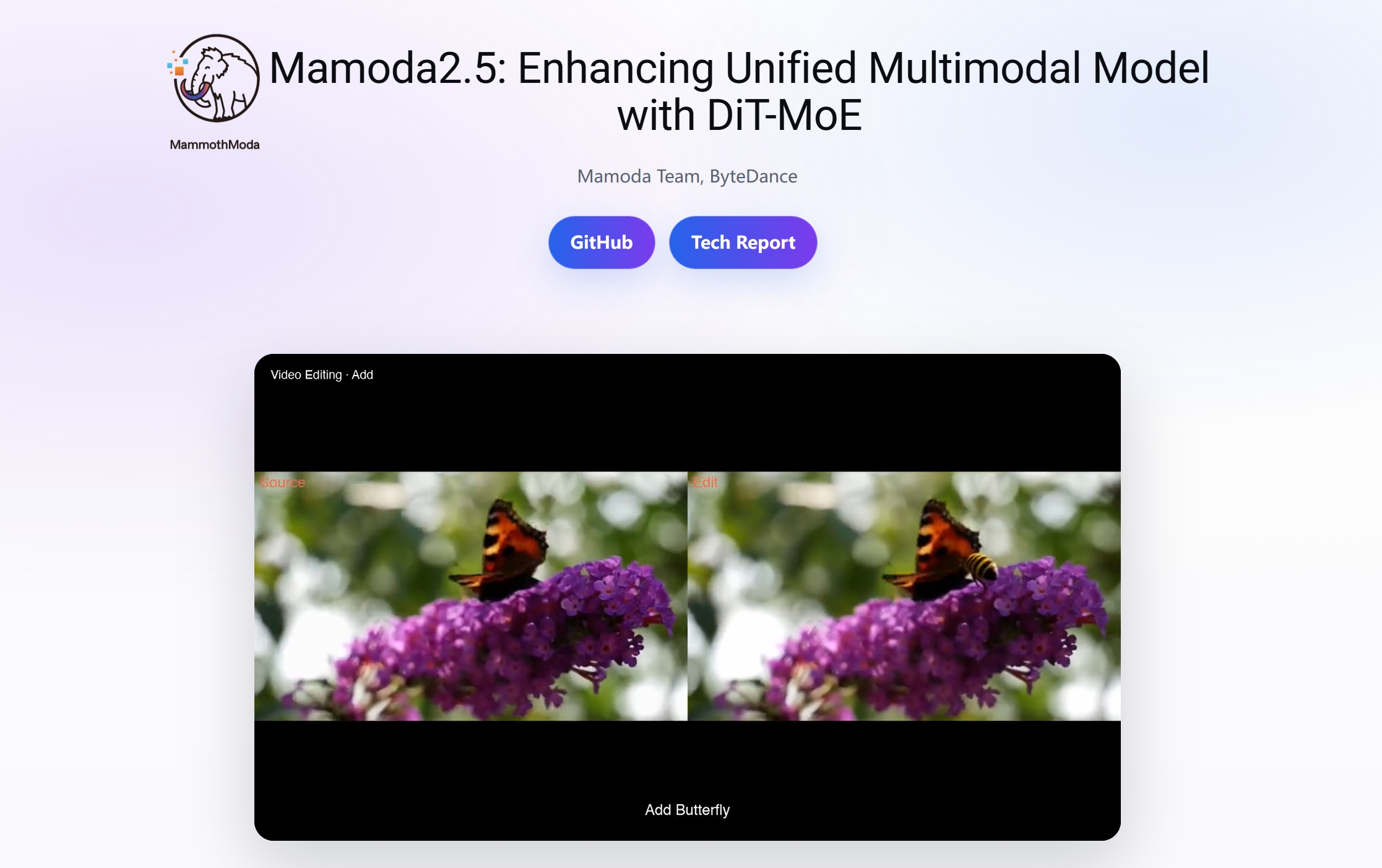
Mamoda2.5的核心优势
- DiT-MoE稀疏架构:模型通过128个专家与Top-8动态路由,仅激活约12%的参数完成推理,相比传统Dense DiT显著降低显存与计算压力,据官方实验数据显示训练收敛速度提升约2.2倍。
- 统一多模态能力:Mamoda2.5将文本理解、图像生成、视频生成与视频编辑整合到统一AR-Diffusion框架中,避免多模型串联造成的信息损失,复杂视频编辑任务中的指令一致性明显提升。
- 视频编辑速度优势:据官方技术报告与OpenVE-Bench测试数据显示,30步编辑模型相比VInO实现12.8倍推理加速,4步蒸馏版延迟降至9.2秒,更适合短视频批量生成场景。
- 长视频生成能力:模型结合Wan2.2高压缩VAE结构,可直接输出720p、93帧视频内容,支持连续镜头运动与复杂场景变化,适用于AI影视预告与动态广告制作工作流。
- 开源与部署灵活:Mamoda2.5采用Apache-2.0协议开放,开发者可结合vLLM与Hugging Face环境部署,适用于AI视频生成API、多语言语音转写与智能体工作流集成场景。
Mamoda2.5的核心功能
- 文生视频生成:用户输入自然语言提示词后,模型基于Qwen3-VL-8B解析语义并调用DiT-MoE生成视频,例如输入“复古胶片风格雨夜街道”,可输出带镜头运动的720p短视频内容。
- 视频编辑能力:模型支持替换、删除、风格迁移与目标添加等视频编辑任务,例如上传人物视频并输入“将白天改成夜景”,系统会自动保持人物动作连续性并完成场景重绘。
- 图像编辑功能:支持局部区域重绘与跨模态编辑,用户上传商品图并输入“更换背景为科技展厅”,模型会保留主体结构与光影关系,适用于电商AI素材生成场景。
- 复杂指令理解:Mamoda2.5通过统一多模态理解模块处理长文本与多对象描述,例如输入包含镜头语言、人物动作与光线变化的复杂提示词,模型仍能保持较高画面一致性。
- 少步蒸馏推理:官方通过联合蒸馏与强化学习优化扩散推理过程,将原本30步视频编辑压缩至4步,减少生成等待时间,更适合AI短视频批量生产与自动化工作流。
Mamoda2.5的技术原理
- AR-Diffusion统一架构:Mamoda2.5采用统一自回归与扩散混合框架,在理解阶段使用Qwen3-VL-8B处理文本与图像语义,在生成阶段通过DiT模块完成高质量视频与图像生成。
- DiT-MoE专家机制:模型生成部分包含128个路由专家,每次仅调用8个专家参与推理,既维持25B模型容量,又减少单次推理计算量,据官方数据显示激活参数约为3B。
- 高压缩VAE结构:系统使用Wan2.2 VAE进行4×16×16高压缩编码,在保证细节还原的同时降低显存占用,使720p视频生成能够在单设备环境中完成。
- 少步蒸馏训练:官方通过强化学习与知识蒸馏联合训练,将传统扩散模型多步采样压缩为4步推理,同时保持运动连续性与主体一致性,减少视频编辑延迟问题。
- 多模态联合训练:Mamoda2.5在图像、视频与文本数据上进行统一训练,使模型能够同时理解镜头语言、物体关系与场景语义,对复杂提示词的执行能力更稳定。
Mamoda2.5与主流模型对比
视频与多模态基准测试对比
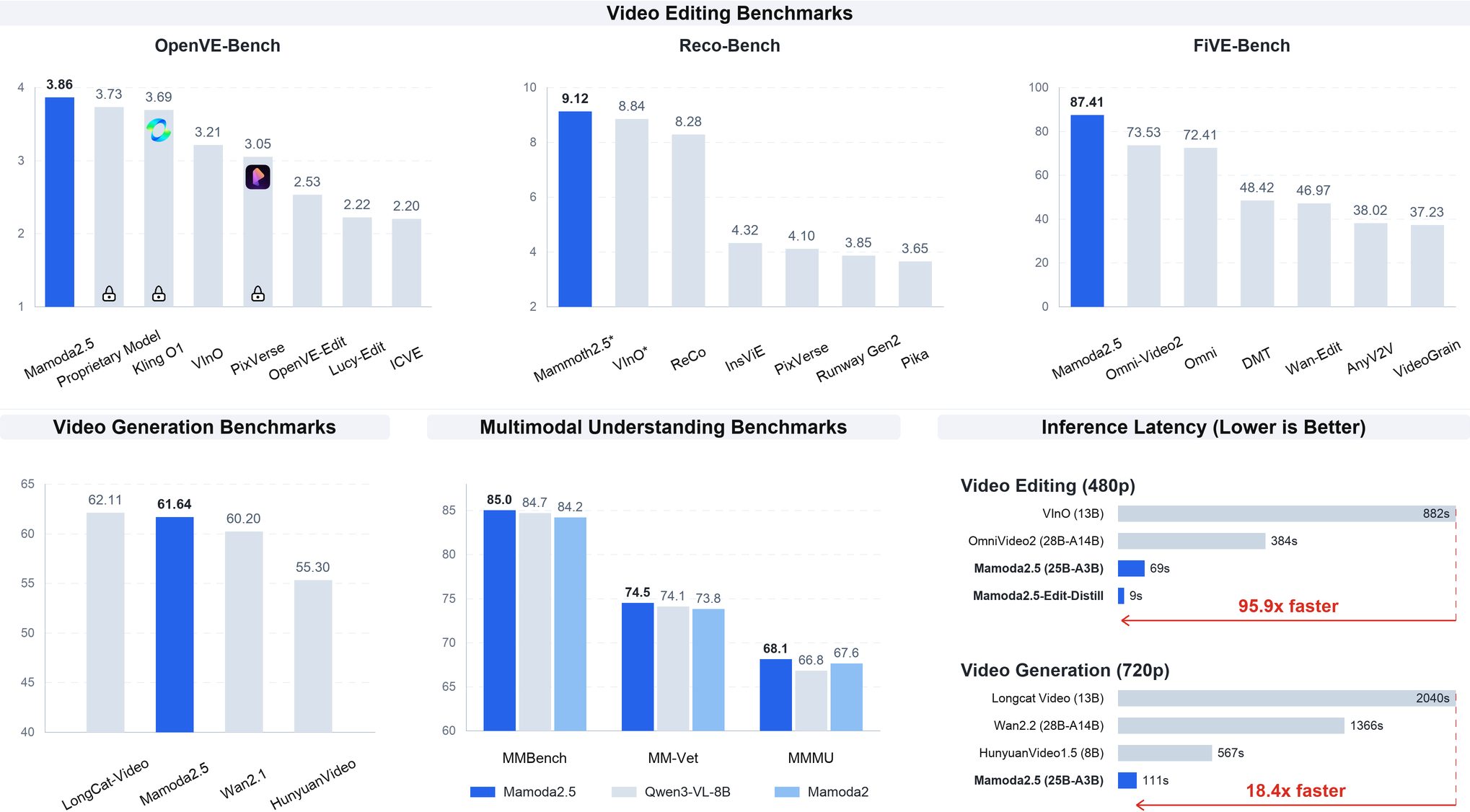
| 测试类别 | 基准测试名称 | Mamoda2.5 得分 | 顶级竞品(得分) | 性能领先幅度 / 排名 |
|---|---|---|---|---|
| 视频编辑 | OpenVE-Bench | 3.86 | Proprietary Model(3.73) | 第1名(+3.5%) |
| 视频编辑 | Reco-Bench | 9.12 | VInO(8.84) | 第1名(+3.2%) |
| 视频编辑 | FiVE-Bench | 87.41 | Omni-Video2(73.53) | 第1名(+18.9%) |
| 视频生成 | Video Gen | 61.64 | LongCat-Video(62.11) | 第2名 |
| 多模态理解 | MMBench | 85.0 | Qwen3-VL-8B(84.7) | 第1名 |
| 多模态理解 | MM-Vet | 74.5 | Qwen3-VL-8B(74.1) | 第1名 |
| 多模态理解 | MMMU | 68.1 | Mamoda2(67.6) | 第1名 |
推理延迟对比
| 场景 | 模型名称 | 参数量 | 推理时间 | 提速倍数 |
|---|---|---|---|---|
| 视频编辑(480p) | VInO | 13B | 882s | 基准(1x) |
| 视频编辑(480p) | OmniVideo2 | 28B-A14B | 384s | 2.3x |
| 视频编辑(480p) | Mamoda2.5 | 25B-A3B | 69s | 12.8x Faster |
| 视频编辑(480p) | Mamoda2.5-Edit-Distill-4 | 未公开 | 9.2s | 95.9x Faster |
| 视频生成(720p) | Longcat Video | 13B | 2040s | 基准(1x) |
| 视频生成(720p) | Wan2.2 | 28B-A14B | 1366s | 1.5x |
| 视频生成(720p) | HunyuanVideo1.5 | 8B | 567s | 3.6x |
| 视频生成(720p) | Mamoda2.5 | 25B-A3B | 111s | 18.4x Faster |
Mamoda2.5目前在视频编辑与多模态理解任务中表现突出。据OpenVE-Bench、FiVE-Bench与MMBench测试数据显示,其多个榜单排名第一。相比传统Dense Diffusion模型,DiT-MoE稀疏架构显著降低推理成本,视频编辑最高实现95.9倍加速,720p视频生成速度相比Longcat Video提升18.4倍。
如何使用Mamoda2.5
- 获取模型:开发者可通过GitHub与Hugging Face下载Preview或Dev版本,建议至少配置80GB以上显存环境,同时安装PyTorch、CUDA与vLLM组件保证推理稳定性。
- 配置推理环境:部署时需启用FP16或BF16模式降低显存占用,视频生成推荐设置720p与93帧参数,长视频任务建议开启分段缓存减少生成中断问题。
- 输入提示词:提示词建议包含镜头、主体、动作与风格信息,例如“低饱和胶片风格+跟拍镜头+雨夜城市”,复杂场景可增加角色描述提高画面一致性。
- 进行视频编辑:上传视频素材后输入编辑指令,例如“删除背景行人并替换为霓虹广告牌”,模型会自动进行时序一致性处理,减少人物抖动与画面闪烁。
- 优化输出效果:若生成内容出现运动异常,可适当增加扩散步数或调整CFG参数,官方建议在高动态镜头中使用30步模式以提升画面稳定性。
Mamoda2.5的局限性
- 实时生成能力有限:虽然Mamoda2.5相比传统扩散模型速度明显提升,但720p视频生成仍需约110秒,暂时无法满足实时视频转写或直播级低延迟生成需求。
- 硬件要求较高:模型总参数达到25B,即使仅激活3B参数,完整部署仍需要高端GPU与较大显存环境,中小团队本地部署成本依然较高。
- 官方API尚未完善:据2026年5月官方项目说明,目前重点仍在研究与开源生态,稳定商业API与标准化计费方案尚未正式发布,企业接入门槛偏高。
Mamoda2.5相关资源
- 项目官网:https://mamoda25.github.io/
- GitHub仓库:https://github.com/bytedance/mammothmoda
- arXiv技术论文:https://arxiv.org/pdf/2605.02641
Mamoda2.5的典型应用场景
- AI短视频制作:输入脚本文案与镜头提示词后,Mamoda2.5可自动生成动态视频内容,并保持角色与场景一致性,适用于短剧、广告与AI电影预告生成。
- 电商商品视频:上传商品图片后输入“生成科技感展示动画”等指令,模型会自动添加镜头运动与背景变化,减少传统三维动画制作成本。
- 影视镜头编辑:创作者可直接对已有视频进行风格迁移或场景替换,例如将白天街景改成赛博朋克夜景,提高后期制作效率与创意表达能力。
- 多语言内容制作:结合AI语音识别、视频字幕自动生成与语音转文字API工作流,Mamoda2.5可用于国际化短视频内容生成与会议记录AI工具场景。
- 智能体工作流:开发者可将Mamoda2.5接入自动化智能体系统,实现从脚本生成、镜头规划到视频输出的完整流程,适用于AIGC内容工厂与营销平台。
Mamoda2.5常见问题
Mamoda2.5怎么用?
Mamoda2.5目前主要通过GitHub与Hugging Face部署使用,开发者需要下载模型权重并配置CUDA与PyTorch环境。
Mamoda2.5免费吗?
Mamoda2.5目前采用Apache-2.0开源协议,研究与商业场景均可使用。
Mamoda2.5和Kling O1哪个好?
据OpenVE-Bench与FiVE-Bench测试数据显示,Mamoda2.5在视频编辑任务中的表现已经超过Kling O1,但Kling O1在商业平台成熟度与在线生成体验方面仍具有优势。
Mamoda2.5支持实时视频生成吗
Mamoda2.5当前主要面向离线视频生成与编辑场景,720p视频生成仍需约110秒。
Mamoda2.5支持API吗?
据2026年5月官方项目说明,目前重点仍在开源模型与研究生态建设,标准化官方API尚未完全开放。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。
相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号