











LongCat是什么
LongCat是由中国互联网企业美团推出并对外开放的大模型系列及对话平台,同时提供在线聊天界面体验,核心模型为LongCat-Flash-Chat。该模型采用混合专家架构,强调在大规模参数规模下实现高效推理与长上下文理解能力。LongCat面向开发者、研究人员及企业应用场景,提供自然语言对话、推理分析与工具调用能力,适用于智能助手集成、复杂任务处理及AI产品研发等方向。其整体定位偏向技术型基础模型平台,而非单一消费级聊天工具。
LongCat的主要功能
- 自然语言对话能力:LongCat-Flash-Chat支持多轮连续对话,能够理解上下文语境并保持语义一致性。其对话能力适用于问答系统、知识助手、企业客服机器人等场景,在长对话链路中具备较好的稳定性与逻辑连贯性。
- 混合专家架构高效推理:模型采用Mixture-of-Experts(MoE)结构,在总参数规模较大的前提下,通过动态激活部分专家参数实现算力优化。这种结构有助于在保持模型表达能力的同时降低单次推理计算压力,更适合高并发或资源受限环境。
- 长上下文处理能力:LongCat支持超长上下文输入,在复杂任务分析、长文档问答、多轮工具调用等场景中具有实际价值。长上下文能力可减少频繁截断带来的信息损失,提升复杂任务连续性处理效果。
- 智能体与工具调用支持:LongCat在Agent类任务上进行了专门优化,支持结构化输出与多步骤任务规划。开发者可以在其基础上构建自动化工作流、外部工具协同系统或决策型智能体应用。
- 代码生成与理解:模型支持主流编程语言代码生成与逻辑解释,可用于辅助开发调试、代码阅读与基础示例生成。对于需要快速验证思路或生成模板的开发场景具有实际辅助意义。
- 文本生成与结构化输出:LongCat支持报告撰写、摘要提取、内容改写与结构化数据生成,适合用于知识整理、资料分析与文档自动化处理等场景。
- 开源部署与扩展能力:模型权重已在 Hugging Face 与 GitHub 开源,开发者可进行本地部署与二次训练,具备较高的可控性与定制空间。
LongCat模型效果如何
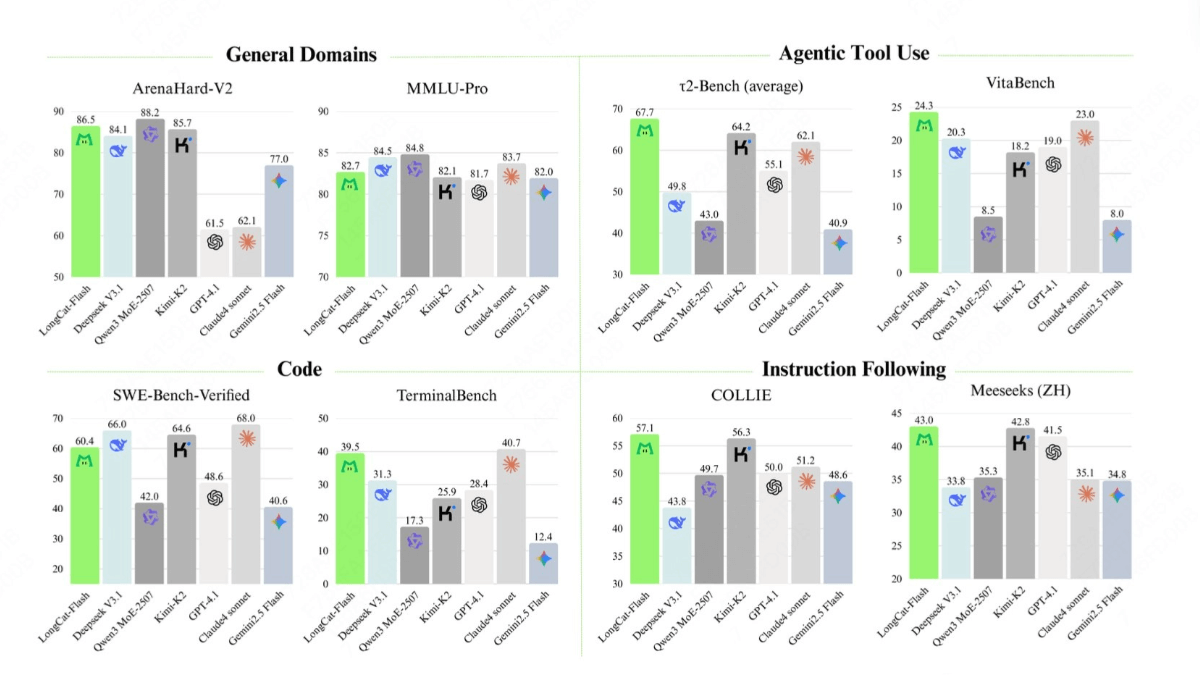
- 通用知识能力(General Domains):在 ArenaHard-V2 测试中,LongCat-Flash 取得 86.5 分,位列第一梯队,高于 DeepSeek-V3.1 的 84.1 和 Kimi-K2 的 85.7;在 MMLU-Pro 中获得 82.7 分,表现接近 Qwen3-MoE-2507 的 84.8,体现出其在跨学科知识理解与复杂问题推理方面的稳定能力。
- 智能体工具使用能力(Agentic Tool Use):在 τ²-Bench(average)中,LongCat-Flash 得分 67.7,明显高于 DeepSeek-V3.1 的 49.8 和 Qwen3-MoE-2507 的 43.0;在 VitaBench 中取得 24.3 分,为图中最高分,超过 Claude-sonnet 的 23.0 和 Kimi-K2 的 19.0,显示其在多步骤任务与工具调用场景中的优势。
- 代码理解与生成能力(Code):在 SWE-Bench-Verified 中,LongCat-Flash 得分 60.4,虽略低于 Claude-sonnet 的 68.0,但高于 GPT-4.1 的 48.6 和 Qwen3-MoE-2507 的 42.0;在 TerminalBench 中获得 39.5 分,仅次于 Claude-sonnet 的 40.7,明显领先 Gemini 2.5 Flash 的 12.4,说明其在终端操作理解与代码执行逻辑上具备较强竞争力。
- 指令遵循能力(Instruction Following):在 COLLIE 测试中,LongCat-Flash 得分 57.1,为图中最高成绩,超过 Kimi-K2 的 56.3 和 GPT-4.1 的 51.2;在 Meeseeks(ZH)中文指令评测中获得 43.0 分,同样位居前列,高于 GPT-4.1 的 41.5 和 Claude-sonnet 的 35.1,体现出其在中英文复杂指令场景下的良好执行能力。
- 整体性能均衡性:从八项评测维度综合来看,LongCat-Flash 在“智能体任务”“指令遵循”和“终端代码能力”三类场景中表现突出,同时在通用知识与编程测试中保持第一梯队水平。需要说明的是,基准测试反映的是标准化环境表现,实际应用效果仍受提示设计、上下文长度、部署资源和业务适配程度影响。
如何使用LongCat
- 访问官方平台:通过LongCat官网进入在线对话界面,直接输入自然语言问题即可开始使用。建议首次使用时从简单指令入手测试模型响应逻辑,避免一次性输入过长复杂任务导致理解偏差。
- 阅读模型文档:在GitHub仓库中查看部署说明与API示例代码,了解模型参数配置与调用方式。注意确认硬件需求与依赖环境版本,避免部署过程中出现兼容性问题。
- 本地或服务器部署:根据官方提供的部署脚本完成环境搭建,常见方式包括GPU服务器部署或云主机推理环境配置。建议在正式部署前进行小规模测试,避免资源不足导致运行失败。
- 通过API集成系统:开发者可将LongCat接入现有系统,通过接口调用实现自动化问答或文本生成。调用时应合理设置温度、最大token长度等参数,以保证输出稳定性。
- 设计高质量提示词:优化提示词是提升输出质量的关键。建议明确任务目标、输出格式及限制条件,避免使用模糊表达或多重指令混杂,以减少偏离结果。
- 建立人工审核机制:在实际应用中应增加结果校验流程,尤其在对外输出内容或涉及重要决策时,应结合人工复核确保准确性。
LongCat的官网地址
- 官网地址:https://longcat.chat/
- Hugging Face 模型库:LongCat Flash Chat 模型页面
- Github 仓库:LongCat Flash Chat 官方 GitHub
LongCat的应用场景
- 智能客服系统:适用于电商与生活服务平台,通过自然语言理解实现自动应答与问题分流,提高响应效率。
- 知识问答系统:可作为企业内部知识库问答引擎,支持长文档理解与多轮问题追问。
- 开发辅助工具:在软件开发场景中辅助生成代码样例与解释复杂逻辑,提高开发效率。
- 内容整理与报告生成:用于会议纪要整理、资料摘要生成及结构化报告输出,减少人工重复性工作。
- 智能体任务构建:在多步骤任务执行场景中,结合外部工具调用实现自动化处理流程。
- 教育辅助应用:为学习场景提供知识讲解与练习解析支持,但仍需结合教师指导。
LongCat的价格与付费方案
- 开源模型权重:LongCat-Flash-Chat已在Hugging Face与GitHub开源,可免费下载模型文件进行本地部署。
- 自部署成本:如采用本地或云服务器部署,成本主要来自GPU算力与存储资源费用,官方未单独收取模型授权费用。
- 在线平台使用:若通过官方在线平台体验,具体使用限制与计费方式以官网公布规则为准,目前公开信息未披露独立商业定价方案。
使用LongCat时需要注意的问题
LongCat作为大模型系统,输出结果仍可能受训练数据偏差与提示词设计影响。在涉及法律、医疗、财务等专业领域时,不应替代专业人士判断。同时,部署与运行大型模型对硬件资源要求较高,需要提前评估算力与维护成本,避免盲目投入。
常见问题 FAQ
- LongCat是聊天机器人吗?
LongCat本质是大模型平台,可用于构建聊天机器人,但其定位更偏向基础模型能力提供方。 - LongCat是否完全免费?
模型权重开源免费,但部署与算力成本需自行承担,具体平台使用规则以官网说明为准。 - LongCat支持多语言吗?
模型具备多语言理解能力,但实际效果取决于训练数据覆盖情况。 - LongCat可以本地部署吗?
可以,需满足GPU算力与存储资源要求,并按照官方文档完成环境配置。 - LongCat适合企业使用吗?
适合有技术团队支持的企业进行自定义部署与系统集成。 - LongCat能替代人工决策吗?
不能完全替代,尤其在高风险专业领域应结合人工判断。 - LongCat和GPT哪个更强?
两者定位不同,LongCat强调开源与可控性,GPT强调商业生态与稳定性。 - LongCat适合个人用户吗?
普通用户可体验在线对话,但完整部署与开发更适合技术背景人群。
总结:LongCat是否值得推荐?
LongCat定位为面向开发者与企业的开源大模型平台,核心优势在于混合专家架构、高效推理机制与可部署扩展能力。对于需要自定义模型能力、构建智能体系统或进行AI研究的团队而言具有参考价值;但对于仅需简单日常对话的普通用户而言,可能更适合选择成熟的商业化平台工具。
相关导航
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号