SenseNova U1快速摘要
SenseNova U1是商汤科技于2026年4月发布的原生统一多模态模型,基于NEO-unify架构实现理解、推理与生成统一建模,适用于图像生成、视觉推理、连续图文创作与多模态Agent系统。
- 模型名称:SenseNova U1系列原生理解生成统一模型(SenseNova-U1 Lite为开源版本)
- 开发公司:商汤科技 SenseTime联合NTU S-Lab共同研发
- 发布时间:2026年4月28日正式发布
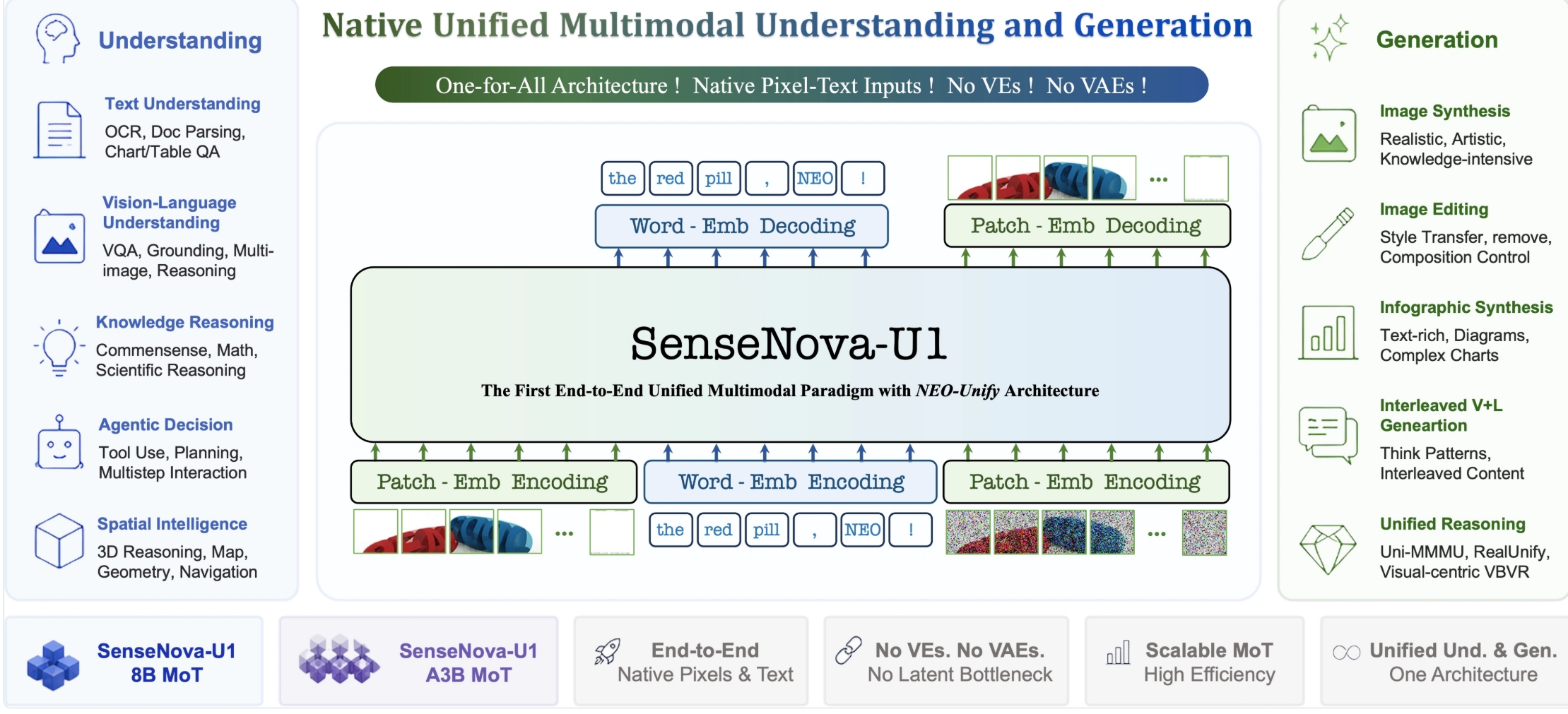
- 核心架构:NEO-unify统一架构,去除视觉编码器(VE)与VAE,构建统一表征空间
- 主要能力:支持图文理解、图像生成、图像编辑、空间推理与连续图文生成
- 模型规格:包含8B-MoT稠密模型与A3B-MoT混合专家模型(MoE)
- 开源情况:已在GitHub与Hugging Face开放权重(Apache风格开源生态)
- 适用场景:多模态AI应用、视觉内容生成、Agent系统与研究型模型开发
- 技术定位:原生统一多模态模型(区别于传统拼接式视觉-语言模型)
- 价格信息:开源版本免费使用,商业API与服务定价未完全公开
SenseNova U1的核心优势
- 原生统一表征空间:基于NEO-unify架构取消视觉编码器与VAE,将图像与文本映射到统一表征空间,实现同一计算路径处理多模态信息,据官方说明可减少跨模态信息损耗,在图像重建任务中PSNR达到31.56,提升视觉保真度与语义一致性。
- 理解生成一体化机制:不同于传统“编码-翻译-生成”流程,U1在单一模型内完成理解与生成联合建模,使图像生成、编辑与推理共享同一参数空间,在多项基准测试中达到开源SOTA水平,提升复杂任务一致性与稳定性。
- 高效MoT混合架构:采用Mixture-of-Transformer设计,结合8B稠密模型与3B级MoE结构,在保持计算效率的同时增强表达能力,在同规模模型中具备更低推理延迟表现,据官方测试在生成任务中延迟优于多数开源多模态模型。
- 统一多任务处理能力:单模型同时支持图像理解、生成、编辑与空间推理任务,无需多模型串联调用,在信息流转过程中减少转换损耗,在复杂视觉任务(如信息图生成)中表现接近商业级模型输出质量。
- 连续图文生成能力:支持多步连续图文创作流程,例如分步骤生成教程图像或从草图逐步生成完整视觉作品,所有步骤共享上下文状态,实现风格与结构一致性提升,在复杂创作任务中减少断裂与失真问题。
SenseNova U1的核心功能
- 图像理解与视觉问答:输入图像与文本问题,模型输出结构化分析与推理结果,例如输入“复杂图表截图+问题”,可输出数据解释与逻辑推理结果,适用于教育分析与视觉信息处理任务。
- 文本驱动图像生成:输入自然语言描述生成高质量图像,例如“科技风海报+蓝色光效+未来城市”,输出符合语义约束的图像结果,基于统一表征机制减少语义偏差。
- 图像编辑与局部修改:输入原始图像与编辑指令,如“替换背景为夜景城市”,模型可保持主体一致性进行局部修改,在电商图像优化与设计辅助中具备应用价值。
- 多模态空间推理:输入图像与问题,例如“判断物体空间关系”,输出逻辑推理结果,适用于机器人视觉理解与空间智能研究任务,在物理布局分析中表现较稳定。
- 连续创作生成流程:支持多轮图文交互生成,如“步骤化食谱图生成”,每一步生成结果保持前一步结构一致性,实现连续创作链路输出,适用于教学与内容生产场景。
SenseNova U1的技术原理
- NEO-unify统一架构:采用原生统一多模态架构,移除视觉编码器(VE)与变分自编码器(VAE),直接在像素与文本之间建立统一表征空间,使不同模态在同一计算路径中融合处理。
- MoT混合Transformer机制:结合稠密模型与混合专家结构(MoE),通过多路径Transformer实现不同任务能力共享,在同一模型中动态分配计算资源以优化推理效率与表达能力。
- 统一多模态训练范式:采用理解与生成联合训练策略,在同一训练过程中同时优化图像理解、生成与编辑任务,使模型具备跨任务一致性学习能力,减少模态割裂问题。
- 像素级直接建模机制:不依赖VAE压缩潜空间,而是直接进行像素级建模,据官方说明该方式提升图像细节保真度,并减少编码误差累积,增强视觉输出一致性。
- 连续上下文建模能力:支持多轮图文交互共享上下文状态,在连续生成任务中保持语义与视觉一致性,使模型能够完成分步骤复杂创作任务,如逐步图像构建与推理链输出。
SenseNova U1与主流模型对比
| 对比维度 | SenseNova U1 | GPT-5.5(OpenAI) | Gemini 3.1 Pro(Google) | LLaVA-OneVision | Qwen2.5-VL |
|---|---|---|---|---|---|
| 模型架构 | NEO-unify原生统一架构,去除VE与VAE,实现像素与语言统一表征空间 | 统一多模态Transformer架构,强化通用推理与Agent能力融合 | 原生多模态Transformer架构,强调长上下文与跨模态检索融合 | 视觉编码器+LLM拼接式架构,依赖外部视觉编码模块 | 视觉编码器+语言模型融合架构,偏传统视觉语言处理范式 |
| 多模态范式 | 原生统一多模态(Unified Representation),图像与文本共享同一语义空间 | 统一接口多模态,内部仍以模块化能力融合不同任务 | 原生多模态输入输出,强调检索增强与上下文扩展 | 分离式多模态处理,图像先编码再语言推理 | 视觉理解增强型多模态模型,生成能力相对有限 |
| 图像生成能力 | 支持原生生成与编辑统一建模,连续图文生成能力突出 | 强生成能力但依赖独立生成模块协同 | 生成能力增强,但偏向辅助型多模态生成 | 生成能力较弱,主要依赖外部扩散模型 | 生成能力中等,偏理解任务导向 |
| 图像理解与推理 | 统一表征空间支持空间推理与复杂视觉逻辑分析 | 强通用推理能力,视觉推理能力依赖训练扩展 | 强化视觉问答与长上下文理解能力 | 视觉理解较强,但跨模态推理有限 | 视觉理解较强,适用于图像问答任务 |
| 连续图文生成 | 支持多步连续创作(草图→生成→编辑),上下文一致性强 | 支持多轮生成,但连续视觉一致性依赖外部控制 | 支持部分连续生成任务,但偏文本驱动 | 不支持原生连续生成流程 | 不支持连续图文生成链路 |
| 开源与可用性 | U1 Lite开源(GitHub / Hugging Face),支持本地部署 | 闭源API服务为主,企业级调用 | 闭源API为主,Google生态集成 | 开源模型,适合研究实验 | 开源模型,适合视觉任务开发 |
SenseNova U1的核心差异在于采用NEO-unify原生统一架构,去除视觉编码器(VE)与VAE,在统一表征空间中直接融合图像与文本信息,从而实现理解、生成与推理的一体化建模。相比GPT-5.5与Gemini 3.1 Pro的模块化多模态结构,U1更强调结构级统一与连续图文生成能力,在一致性与编辑任务中表现更稳定。与LLaVA-OneVision、Qwen2.5-VL等开源视觉语言模型相比,U1在跨模态统一性与生成链路完整性上更进一步,但在生态成熟度与商业API能力方面仍相对有限。整体来看,其优势集中在原生统一架构与连续多模态生成范式。
如何使用SenseNova U1
- 模型获取与部署:从GitHub或Hugging Face下载SenseNova-U1 Lite权重,建议使用8B-MoT版本进行基础测试,部署环境建议GPU显存16GB以上,以保证图像生成任务稳定运行。
- 推理环境配置:使用PyTorch或Transformers框架加载模型,基础参数建议设置
temperature=0.7,top_p=0.9,用于平衡生成稳定性与多样性,适用于图像生成与文本推理任务。 - 输入任务构建:输入可为文本、图像或图文组合,例如“生成科技海报+蓝色未来风格”,或“分析图表数据并解释趋势”,系统将统一映射至多模态表征空间进行处理。
- 连续生成控制:在多步骤任务中保持同一session上下文,例如“步骤1草图→步骤2细化→步骤3上色”,通过共享上下文实现一致性输出,适合复杂创作流程控制。
- 效果优化策略:通过增强提示词细节(如光影、构图、风格约束)提升生成质量,在编辑任务中增加局部约束描述可减少误修改,提高输出可控性。
SenseNova U1的局限性
- 生态工具链不完善:相比成熟闭源模型,当前插件、API与企业级工具链仍在建设中,原因在于2026年刚开源发布,官方预计后续版本将逐步完善开发者生态。
- 高阶模型未完全开放:当前主要开放8B与3B级轻量版本,更大规模模型尚未发布,导致在超复杂推理任务中能力仍有限,官方表示后续将持续Scale更大模型。
- 商业接口未标准化:API计费体系与企业级服务尚未完全公开,主要以研究开源为主,商业部署仍需等待官方后续统一接口规范。
SenseNova U1相关资源
- GitHub仓库:https://github.com/OpenSenseNova/SenseNova-U1
- HuggingFace模型库:https://huggingface.co/collections/sensenova/sensenova-u1
SenseNova U1的典型应用场景
- AI视觉内容生产:输入营销需求如“科技产品海报”,系统输出高质量图像并支持后续编辑,适用于广告设计、电商视觉与内容创作流程。
- 连续图文教学生成:输入教学步骤如“牛排制作流程”,系统逐步生成图文步骤并保持一致性,适用于教育内容与知识可视化场景。
- 多模态Agent系统:输入图像任务与文本指令,系统自动推理并生成结果,可用于智能体系统中的视觉工具调用与决策链构建。
- 视觉数据分析:输入图表或复杂图像,输出结构化分析结果,用于数据解读、科研辅助与商业分析场景。
- 机器人视觉推理:输入空间图像与任务指令,系统输出空间关系与执行建议,适用于具身智能与机器人视觉系统研究。
SenseNova U1常见问题
SenseNova U1怎么用?
SenseNova U1通过开源权重本地部署或Hugging Face加载使用,输入文本或图像即可生成结果。建议优先使用8B版本测试推理能力。
SenseNova U1是免费的吗?
开源版本SenseNova-U1 Lite可免费使用,适用于研究与实验用途
SenseNova U1和GPT-5.5、Gemini 3.1 Pro哪个好?
U1偏原生统一多模态与连续生成,GPT-5.5强通用推理与Agent,Gemini强长上下文与检索,取决于使用场景而非绝对优劣。
SenseNova U1支持哪些功能?
支持图像生成、图像理解、图像编辑、空间推理与连续图文创作等功能,通过统一表征空间实现多任务融合处理,减少模型切换成本,适用于多模态AI应用开发。
SenseNova U1有什么局限性?
当前主要局限在于生态工具链尚不完善、商业API未完全开放以及大规模模型尚未发布。据官方规划,后续将持续扩展模型规模并完善开发者生态体系。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。
相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号