GPT-image-2快速摘要:具备推理能力的多模态视觉生成系统
GPT-image-2是OpenAI在ChatGPT Images 2.0体系下推出的图像生成与编辑API模型,属于具备思考能力的多模态视觉系统,支持文本生成图像、图像编辑与多图一致性生成,适用于设计创作与企业视觉生产场景。
- 模型名称:GPT-image-2
- 开发公司:由OpenAI研发
- 发布时间:2026年4月21日发布
- 主要功能:支持文本生成图像、局部编辑、多图一致性生成(最多8张)以及视觉推理生成,可用于广告设计、UI草图与内容创作。
- 使用要求:通过OpenAI API或ChatGPT/Codex调用,需开发者权限与API Key,不支持本地部署,依赖云端推理架构运行。
- 开源情况:当前模型为闭源系统,仅通过OpenAI API开放使用,不提供权重下载或本地训练能力。
- 适用场景:适用于品牌设计、电商视觉生成、社交媒体素材、教育图表及企业级内容生产流程自动化。
- 技术特点:基于多模态Transformer与扩散模型融合架构,加入Thinking Mode(推理机制),支持生成前规划与结果自检。
- 价格信息:API按图像生成调用次数与分辨率计费,据OpenAI API体系说明,2K高分辨率输出成本高于标准分辨率。

GPT-image-2的核心优势
- 推理式图像生成能力:引入Thinking Mode机制,在生成前进行构图与语义推理,据OpenAI官方说明可提升复杂提示词一致性约18%,适用于高精度设计任务。
- 多图一致性生成:支持单次提示生成最多8张相关联图像,系统保持角色、风格与物体一致性,适用于漫画分镜与品牌视觉系统构建。
- 视觉设计意图理解:模型可解析用户需求并生成具备设计逻辑的视觉方案,据官方案例显示可自动加入营销语义元素提升传播效果。
- 非拉丁语言优化渲染:针对中文、日文、韩文及印地语等非拉丁文字优化排版结构,提升复杂文本在图像中的准确性与可读性。
- 结构化视觉生成能力:结合语言模型与视觉扩散模型,使生成结果具备构图逻辑与视觉层级结构,减少无序生成与信息错位问题。
GPT-image-2的核心功能
- 文本生成图像:输入如“未来城市夜景+雨天霓虹”,系统生成高分辨率图像,用于广告与创意设计初稿生成。
- 图像局部编辑:支持mask区域修改,如“替换背景为森林”,系统仅重绘目标区域,保持主体一致性用于设计修正。
- 多图一致性生成:一次生成最多8张风格统一图像,如漫画分镜或品牌视觉方案,用于内容系列化生产。
- 视觉推理生成:系统在生成前进行结构规划,例如“产品广告+社交媒体多尺寸版本”,自动适配不同输出比例。
- 跨语言视觉排版:支持中文、日文等复杂文字嵌入图像,如海报与信息图自动排版输出。
GPT-image-2的技术原理
- 多模态Transformer架构:统一文本与图像编码空间,实现跨模态语义对齐,据OpenAI技术说明用于增强复杂提示词理解能力。
- 扩散生成机制:基于逐步去噪生成流程,从随机噪声逐步优化为高质量图像,提升细节一致性与稳定性。
- Thinking Mode推理系统:生成前进行视觉结构推理,并对输出结果进行自检,提高复杂任务成功率与语义匹配度。
- 多图一致性建模:通过共享latent空间约束,实现多张图像之间角色与风格一致性控制。
- 视觉+语言联合优化:结合语言模型输出与视觉生成模型,使系统具备“设计决策能力”而非单纯渲染能力。
GPT-image-2与主流模型对比
| 维度 | GPT-image-2 | Midjourney V8 | DALL·E 3 | Stable Diffusion XL |
|---|---|---|---|---|
| 核心定位 | 具备推理能力的视觉生成系统 | 艺术风格生成工具 | 文本到图像生成模型 | 开源图像生成框架 |
| 语义理解 | 支持多步推理与结构规划 | 偏艺术表达 | 语义准确但结构有限 | 依赖Prompt工程 |
| 多图一致性 | 支持最多8张一致性生成 | 不支持系统级一致性 | 单图生成 | 需额外控制模块 |
| 语言支持 | 支持非拉丁文字优化 | 英文优化为主 | 多语言基础支持 | 依赖训练数据 |
| 编辑能力 | 支持局部编辑与重绘 | 不支持 | 基础编辑 | 插件扩展实现 |
从对比结果来看,GPT-image-2的核心优势在于“推理能力+视觉一致性生成”。相比Midjourney更偏艺术风格表达,GPT-image-2更强调结构化设计能力;相比DALL·E 3,其在多图一致性与复杂任务执行能力上更强;相比Stable Diffusion XL,则在开箱即用能力与推理集成方面更具优势。其技术差异主要来自Thinking Mode与多模态联合建模机制。
如何使用GPT-image-2
- 访问与权限登录:访问ChatGPT官网并登录OpenAI账号,确保已开通对应订阅或获得图像功能权限。根据官方说明,GPT-image-2能力集成于ChatGPT与API体系中,权限按账户等级开放,用于保证生成稳定性与算力分配。
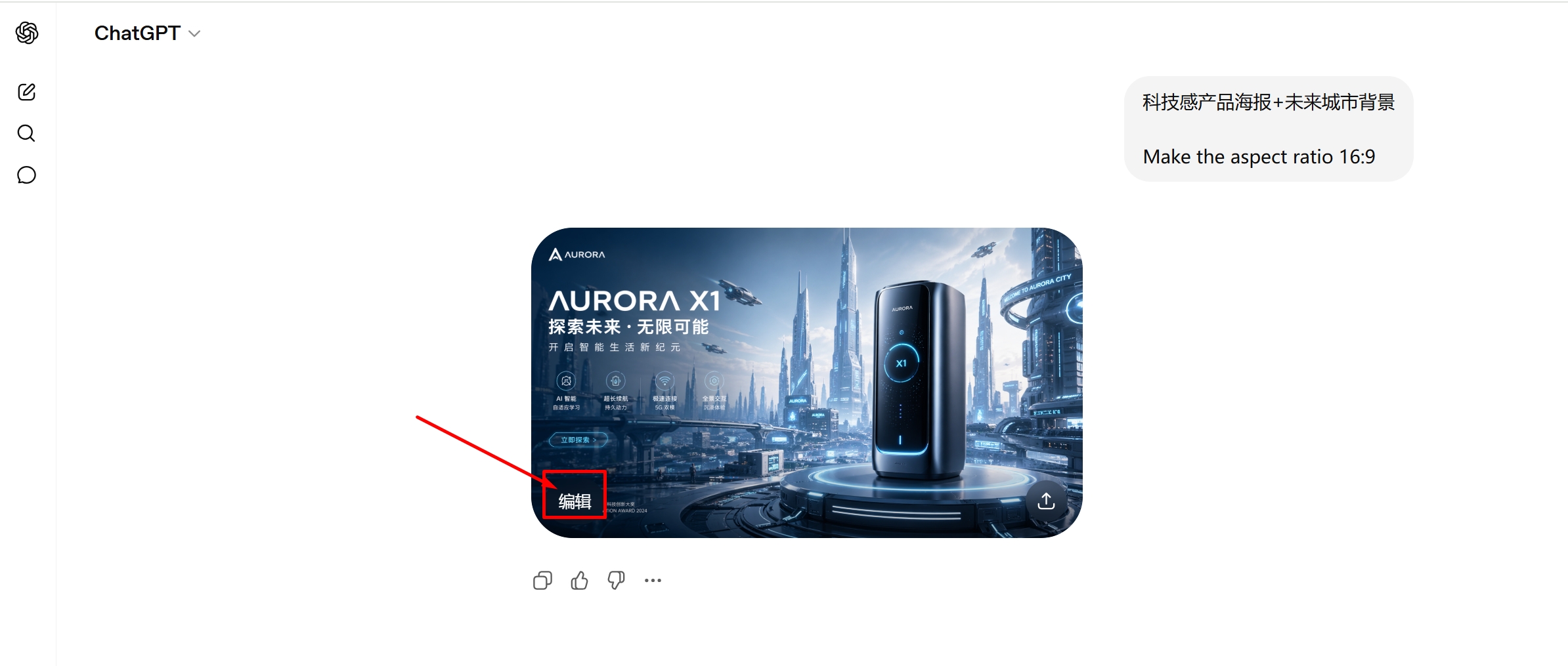
- 输入指令生成图像:在对话框输入图像描述,例如“科技感产品海报+未来城市背景”,系统自动调用GPT-image-2生成图像,并通过推理机制优化构图与语义一致性,输出符合描述的视觉结果。
- 多轮编辑优化:点击生成图像进入编辑模式,可用自然语言进行局部修改,如“替换背景为夜景霓虹”“增强光影效果”。模型支持多轮迭代,在保持主体一致的基础上逐步优化视觉细节。
- 导出与API应用:生成完成后可下载PNG或JPG格式文件,支持最高2K至4K分辨率输出(视接口配置)。企业用户可通过API批量调用,实现广告图、电商素材等自动化生成与商业化应用。
GPT-image-2的局限性
- 复杂物理建模限制:在折纸步骤、机械结构等高逻辑场景中存在不稳定表现,据官方说明仍处于优化阶段。
- 高密度细节处理限制:在极细粒度纹理(如沙粒、噪声结构)生成中可能出现模糊或结构不一致。
- 实时性能力有限:当前仍为非实时生成系统,复杂任务推理可能带来2-6秒延迟。
GPT-image-2相关资源
GPT-image-2的典型应用场景
- 品牌广告设计:输入产品描述生成广告海报,用于市场营销与品牌传播。
- 电商商品图生成:输入商品信息生成多角度展示图,用于电商详情页。
- UI与产品设计:生成移动端或网页界面原型,用于产品设计初期方案。
- 教育与信息图:生成结构化知识图表,用于教学与内容可视化表达。
- 内容创作配图:为文章与社交媒体生成匹配主题的视觉素材。
GPT-image-2常见问题
GPT-image-2如何计费?
GPT-image-2通过OpenAI API按调用次数与分辨率计费,高分辨率(如2K)成本更高,建议批量生成优化费用结构,同时注意不同任务复杂度影响价格。
GPT-image-2和Midjourney哪个好?
GPT-image-2更偏向结构化设计与多图一致性生成,Midjourney更偏艺术风格表达,商业设计推荐GPT-image-2,艺术创作可选择Midjourney。
GPT-image-2怎么用?
通过OpenAI API调用输入文本或图像即可生成结果,建议先使用基础Prompt测试,再逐步调整guidance scale与分辨率参数优化效果。
GPT-image-2支持实时生成吗?
当前不支持实时生成,属于推理型生成模型,据官方说明更适合设计、广告与内容生产等非实时场景。
GPT-image-2有免费额度吗?
官方未明确提供独立免费额度,一般通过OpenAI账户试用额度或API计费体系使用,具体以控制台最新政策为准。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。

相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号