GPT-5.5快速摘要:大语言模型能力与应用场景
GPT-5.5是OpenAI于2026年4月发布的大语言模型,支持超长上下文、多模态推理与智能体任务执行,适用于编程、研究分析与复杂知识工作。
- 模型名称:GPT-5.5,定位为GPT-5.4后的增量旗舰版本。
- 开发公司:OpenAI
- 发布时间:2026年4月23日
- 主要功能:支持代码生成、复杂任务拆解、计算机操作、多轮推理与网页研究,据官方Terminal-Bench 2.0测试准确率82.7%。
- 上下文长度:ChatGPT与Codex版本支持400K上下文,API版本支持1M上下文窗口,据官方文档显示。
- 技术特点:强调低延迟推理与更高token效率,据官方说明同类任务token消耗低于GPT-5.4。
- 开源情况:闭源商业模型,目前支持API调用,不提供模型权重下载,不属于开源大模型路线。
- 价格信息:API标准价格输入5美元/百万tokens、输出30美元/百万tokens,据2026年4月官方定价。

GPT-5.5的核心优势
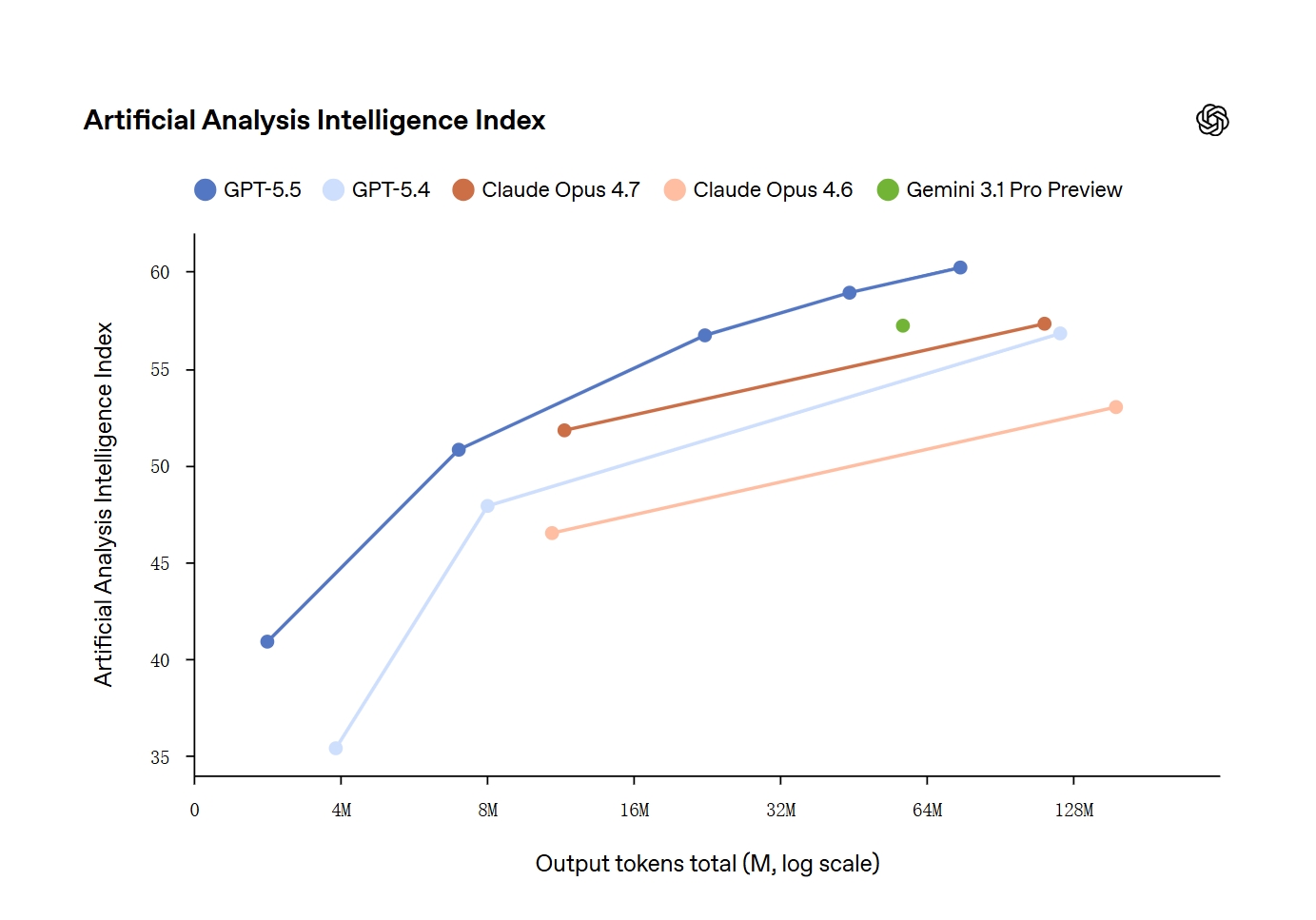
- 智能体任务执行:采用长链推理结合工具调用机制处理复杂任务,可自动规划步骤并检查结果。根据Terminal-Bench 2.0测试达到82.7%,高于Claude Opus 4.7的69.4%,在代码代理与软件操作类任务中输出稳定性更高。
- 超长上下文能力:支持最高1M上下文长度,结合上下文压缩与检索增强机制维持长任务一致性。在大型代码仓分析、长文档审阅和科研任务中可减少上下文丢失,据官方说明较GPT-5.4压缩质量进一步优化。
- 多模态推理协同:支持文本、图像理解及跨工具工作流组合处理,可在单次任务中完成图文分析到结构化输出。根据BrowseComp测试84.4%,高于GPT-5.4,对知识工作自动化价值更高。
- 编码与调试效率:强化代理式编程能力,在Expert-SWE内部测试73.1%,高于GPT-5.4的68.5%。支持需求拆解、代码修改、测试验证闭环,在复杂软件工程场景更适合作为AI编码助手。
- 成本效率优化:虽然单token价格提高,但任务级token效率提升明显。据官方与第三方成本测算,同复杂Codex任务总体成本未同比例上升,适合关注结果成本而非单价的API开发场景。
GPT-5.5性能表现
- Agentic编程性能:据OpenAI 2026年4月评测,GPT-5.5在Terminal-Bench 2.0达到82.7%,高于GPT-5.4的75.1%,也高于Claude Opus 4.7的69.4%;Expert-SWE达到73.1%,体现长链编码与工具协同能力提升。
- 知识工作能力:在GDPval测试中达到84.9%,较GPT-5.4提升1.9个百分点;OSWorld-Verified为78.7%,Tau2-bench Telecom无提示调优达到98.0%,显示复杂工作流执行稳定性增强。
- 科研与推理表现:FrontierMath Tier1-3达到51.7%,Tier4达到35.4%,明显高于GPT-5.4;GeneBench由19.0%提升至25.0%,BixBench达80.5%,说明科研推理与数据分析能力进一步增强。
- 长上下文与效率:Graphwalks BFS 1M F1达到45.4%,显著高于GPT-5.4的9.4%;512K-1M MRCR准确率74.0%,高于前代36.6%。据官方说明,同时保持与GPT-5.4近似延迟,并实现20%以上推理速度优化。
GPT-5.5的核心功能
- 代码生成功能:基于代理式代码推理机制,可输入“重构10个模块并生成测试用例”,输出包含代码修改、验证脚本与错误检查结果。据SWE-Bench Pro公开测试58.6%,适合工程开发与自动化编程。
- 复杂研究分析:输入科研问题或数据任务,例如上传实验数据与研究目标,可输出分析路径、统计解释与下一步实验建议。据GeneBench相关官方评估,在多阶段科研任务有性能提升。
- 计算机任务执行:支持跨工具工作流操作,例如输入“整理表格并生成报告”,模型可拆解任务、调用工具并完成输出。根据OSWorld-Verified测试78.7%,高于多数同类模型。
- 长文档处理:可处理大规模合同、代码库或知识库输入,结合长上下文与检索机制输出摘要、对比与结构化结论。输入数十万token文档时仍适合维持任务连续性,适合知识管理场景。
- API集成能力:支持通过Responses与Chat Completions接口调用,可配置温度、最大token与工具参数,例如temperature 0.2用于高稳定任务输出,适用于开发者部署与自动化系统集成。
GPT-5.5的技术原理
- Transformer架构增强:基于大规模Transformer架构演进,结合强化学习后训练与任务规划优化机制,实现长链推理能力增强。支持最高1M上下文窗口,适合长任务推理场景。
- 工具调用推理机制:采用模型推理与外部工具协同路线,不仅生成文本,还能规划调用浏览、代码执行等工具完成任务。Toolathlon测试55.6%,体现该机制有效性,据官方测试数据表明。
- 推理持续性优化:通过长期任务状态维持机制改善多步骤任务中中途偏航问题,例如复杂调试任务中保持目标一致性,这类能力是传统对话模型与代理模型的重要差异点。
- 多模态统一处理:文本与视觉输入在统一推理路径处理,例如输入图表加问题,输出可同时包含数据解读与文本推理。相比传统多模态外挂方案,一致性更高。
- 安全与风险控制:据官方系统卡说明,新增网络安全与高风险任务分类器,并通过约200个早期伙伴红队测试。能力增强同时配套防滥用机制,是技术架构的一部分。
GPT-5.5与主流模型对比
| 对比维度 | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro | DeepSeek V4 Preview |
|---|---|---|---|---|
| 上下文长度 | 1M | 约500K级 | 1M | 1M |
| Terminal-Bench 2.0 | 82.7% | 69.4% | 68.5% | 公开预览中 |
| FrontierMath Tier1-3 | 51.7% | 43.8% | 36.9% | 未统一披露 |
| 多模态能力 | 支持 | 支持 | 支持 | 部分支持 |
| API输入价格 | $5/1M | 更高 | 平台差异 | 低价路线 |
从公开测试看,GPT-5.5主要优势集中在长链推理、代理式编码和复杂知识工作。根据OpenAI与第三方测试数据,Terminal-Bench和FrontierMath领先主要来自训练规模、推理后训练强化以及工具协同设计。Claude Opus 4.7在部分SWE任务仍有竞争力,Gemini 3.1 Pro在长上下文与生态集成有优势,DeepSeek V4 Preview则在开源与成本侧更有吸引力。若关注高复杂推理与任务执行,GPT-5.5适配度更高;若关注开放部署或低成本,大型开源模型更有吸引力。
如何使用GPT-5.5
- 选择入口与版本 通过ChatGPT Plus、Pro或API使用GPT-5.5;复杂高准确任务优先选择Pro变体。API调用建议先从最大输出
4096-8192 token配置测试稳定性。 - 设置任务参数 对开发任务建议temperature设为0.2至0.4,研究创作可设0.6。长任务配合上下文分段输入,每段控制50K-100K token有助稳定输出。
- 启用工具协同 使用代码执行、浏览或文件上传组合能力,例如上传代码库后要求模型生成修复方案,可显著提升任务完成度并减少幻觉问题。
- 进行提示优化 采用目标、约束、输出格式三段式提示,例如明确“输出JSON结构+逐步验证”,有助复杂任务质量提升,尤其适合API工作流接入。
- 监控成本与效果 长任务应记录token消耗与输出成功率,通过批处理模式或Flex定价优化成本。据官方价格说明批量模式成本可下降约50%。
GPT-5.5的局限性
- 价格门槛: 输出token价格高于前代模型,对高频API调用成本压力更大。原因在于更高计算资源需求。官方已提供Batch与Flex定价作为缓解方案,但仍偏企业导向。
- 长上下文压缩风险: 虽支持1M上下文,但超长任务中仍可能出现上下文压缩导致信息遗漏。部分开发者测试反馈存在状态丢失问题,官方后续可能继续优化记忆稳定性。
- 闭源部署限制: 不支持本地私有部署,不适合有严格数据主权要求的场景。该限制来自商业闭源路线,官方目前未公开开放权重计划。
GPT-5.5相关资源
- 官方介绍页:Introducing GPT‑5.5
GPT-5.5的典型应用场景
- 软件开发:输入需求说明与代码仓,操作中调用代码分析工具,输出实现代码、测试脚本与修复建议,对研发效率提升价值较高。
- 科研辅助:输入实验数据或研究问题,模型执行分析推理并输出研究假设与数据解释,适合知识密集型研究辅助。
- 企业知识工作:输入合同、报表和会议资料,操作中结合检索与结构化输出,生成报告与决策摘要,提高知识处理效率。
- 智能体自动化:输入多步骤任务目标,例如跨系统整理数据,模型规划并调用工具执行,适用于Agent工作流场景。
- 教育与训练:输入复杂题目或案例,输出逐步推导与解释过程,可用于推理训练、代码教学和专业辅导场景。
GPT-5.5常见问题
GPT-5.5怎么用?
GPT-5.5可通过ChatGPT订阅版或API调用使用。复杂任务建议启用文件上传与工具协同,并将温度控制在0.2到0.4提高稳定性。长任务建议拆分输入并采用结构化提示,避免上下文压缩影响效果。
GPT-5.5如何计费?
据2026年4月官方定价,标准API输入5美元每百万tokens,输出30美元每百万tokens。批处理模式成本更低,适合高频调用。使用前应评估token消耗,并关注Priority或Flex模式差异。
GPT-5.5和Claude Opus 4.7哪个好?
根据Terminal-Bench 2.0测试,GPT-5.5准确率82.7%,高于Claude Opus 4.7。复杂代理任务与编程更适合GPT-5.5,而部分代码修复任务Claude仍具竞争力,应按任务类型选择。
GPT-5.5支持免费使用吗?
当前主要向Plus、Pro、Business和Enterprise开放,免费层未作为标准配置提供。普通用户如需测试,可关注官方试用政策变化,API调用则需开通付费账户。
GPT-5.5支持实时智能体任务吗?
目前支持工具协同任务执行,但严格意义实时流式Agent能力仍依赖具体产品接口配置。复杂自动化任务建议结合Codex或API工作流部署,并测试延迟与任务稳定性。

 浙公网安备33010202004812号
浙公网安备33010202004812号