Claude Opus 4.7快速摘要:
Claude Opus 4.7是Anthropic研发的大语言模型,支持复杂推理、多模态理解与代码生成,适用于软件开发与企业级智能应用场景。
- 模型名称:Claude Opus 4.7
- 开发公司:Anthropic,专注AI安全与大模型研发
- 发布时间:2026年4月16日正式发布,属于Opus 4.6最新迭代版本
- 主要功能:支持代码生成、多模态理解、长任务推理与复杂文档处理,据官方测试显示在多项任务优于Opus 4.6
- 使用要求:需通过Claude平台或API调用使用,支持Amazon Bedrock、Vertex AI与Foundry接入
- 开源情况:未开源,采用闭源商业模型策略,主要面向企业级与开发者市场
- 适用场景:适用于软件开发、金融分析、复杂文档处理及多模态数据理解等场景
- 技术特点:支持xhigh推理强度控制、高分辨率视觉输入与文件级记忆能力
- 价格:输入$5/百万tokens,输出$25/百万tokens,与Opus 4.6保持一致

Claude Opus 4.7的核心优势
- 复杂推理能力提升:通过引入更高效的推理调度机制与xhigh effort模式,使模型在多步推理中能进行更深层思考,据官方测试显示在复杂编码任务中成功率明显高于Opus 4.6,适用于长链路决策与复杂逻辑分析场景
- 指令遵循精度增强:采用更严格的指令解析与执行机制,减少语义偏差,使模型在执行复杂提示词时更加准确,据官方反馈提示词执行一致性显著提升,但需重新优化旧prompt以适配新行为
- 高分辨率视觉能力:支持最长边2576像素图像输入,基于增强视觉编码器实现细节级解析,据官方说明较前代提升超过3倍像素处理能力,适用于UI识别与复杂图表分析
- 长任务一致性与稳定性:通过改进上下文管理与任务分解能力,在长时间运行任务中保持一致输出,据内部测试在长上下文推理与多阶段任务中表现更稳定
- 安全与对齐机制优化:引入Glasswing相关安全策略与自动检测机制,对高风险请求进行识别与阻断,据官方安全评估显示模型在抗提示注入与误用防护方面有所提升
Claude Opus 4.7的核心功能
- 代码生成与自动化开发:基于大规模代码训练与推理机制,支持复杂代码生成与重构,例如输入完整项目需求可输出多文件结构代码,据官方测试在软件工程任务中优于Opus 4.6
- 多模态视觉理解:通过视觉编码器处理高分辨率图像输入,如输入UI截图可输出组件结构与代码说明,据官方文档显示支持细粒度像素级分析
- 文档推理与分析:结合长上下文与语义建模能力,可对长文档进行总结与逻辑分析,例如输入100页报告生成关键结论,适用于法律与金融分析场景
- 智能任务代理执行:支持长任务自动执行,通过多轮推理与任务分解完成复杂目标,例如输入“构建API系统”可输出完整流程方案
- 记忆与上下文管理:通过文件系统级记忆能力记录多轮任务信息,在后续任务中自动引用历史数据,据官方说明可减少重复输入上下文需求
Claude Opus 4.7的技术原理
- Transformer架构优化:基于改进的Transformer架构,结合大规模预训练与指令微调,实现更强语义理解能力,支持长上下文推理但具体长度官方未披露
- 多模态融合机制:通过视觉编码器与文本模型融合,实现图像与文本联合推理,例如输入图像与文本指令可生成结构化输出
- 推理强度控制机制:引入effort参数(low、high、xhigh等),控制推理深度与延迟,实现性能与速度平衡,适用于不同复杂度任务
- 记忆增强机制:通过文件系统存储历史上下文,实现跨会话信息复用,例如在多阶段开发任务中自动调用历史数据
- 安全对齐训练:结合对抗训练与安全规则学习,降低模型误用风险,例如自动识别高风险请求并进行限制
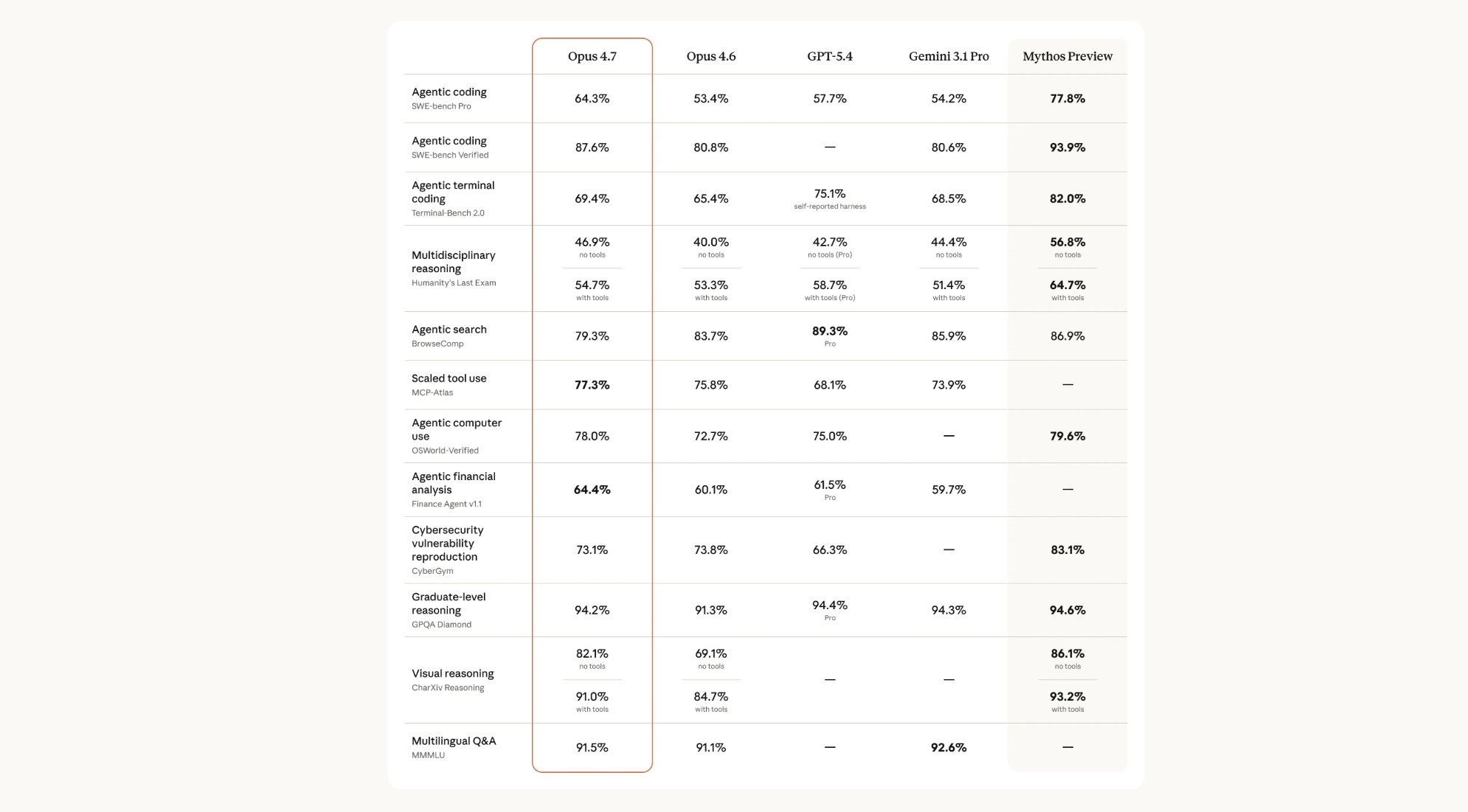
Claude Opus 4.7与主流模型对比
| 对比维度 | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro | Claude Opus 4.6 | Mythos Preview |
|---|---|---|---|---|---|
| Agentic编码(SWE-bench Pro) | 64.3% | 57.7% | 54.2% | 53.4% | 77.8% |
| Agentic编码(SWE-bench Verified) | 87.6% | – | 80.6% | 80.8% | 93.9% |
| 终端编码能力(Terminal-Bench 2.0) | 69.4% | 75.1% | 68.5% | 65.4% | 82.0% |
| 跨学科推理(无工具) | 46.9% | 42.7% | 44.4% | 40.0% | 56.8% |
| 跨学科推理(工具增强) | 54.7% | 58.7% | 51.4% | 53.3% | 64.7% |
| Agentic搜索(BrowseComp) | 79.3% | 89.3% | 85.9% | 83.7% | 86.9% |
| 工具调用能力(MCP-Atlas) | 77.3% | 68.1% | 73.9% | 75.8% | – |
| 计算机操作(OSWorld) | 78.0% | 75.0% | – | 72.7% | 79.6% |
| 金融分析(Finance Agent) | 64.4% | 61.5% | 59.7% | 60.1% | – |
| 网络安全(CyberGym) | 73.1% | 66.3% | – | 73.8% | 83.1% |
| 学术推理(GPQA Diamond) | 94.2% | 94.4% | 94.3% | 91.3% | 94.6% |
| 视觉推理(CharXiv 无工具) | 82.1% | – | – | 69.1% | 86.1% |
| 视觉推理(CharXiv 工具增强) | 91.0% | – | – | 84.7% | 93.2% |
| 多语言能力(MMLU) | 91.5% | – | 92.6% | 91.1% | – |
从官方基准测试数据来看,Claude Opus 4.7在SWE-bench Pro(64.3%)和Verified(87.6%)等编码任务中明显优于Opus 4.6,体现出更强的软件工程能力。与GPT-5.4相比,其在工具调用与代码生成上更有优势,但在搜索类任务略弱。相比Gemini 3.1 Pro,Claude在工程与金融分析场景更突出,而Gemini在多语言表现略优。整体来看,Claude Opus 4.7在推理稳定性与复杂任务执行方面处于主流模型第一梯队,而Mythos Preview仍属于更高能力层级模型。
如何使用Claude Opus 4.7
- 获取访问权限:注册Claude平台或通过API获取密钥,例如在Anthropic平台创建账号并生成API Key,用于后续调用
- 配置模型参数:选择claude-opus-4-7模型并设置effort参数(如high或xhigh),建议复杂任务使用xhigh以提升推理质量
- 输入任务指令:提供明确且结构化的提示词,例如“生成Python API服务,包含认证模块”,提高模型理解准确性
- 优化输出结果:根据输出进行多轮调整,如限制token长度或要求精简表达,以降低成本并提升结果质量
- 部署应用:通过API接入实际业务系统,如自动代码生成工具或文档分析系统,实现生产级应用
Claude Opus 4.7的局限性
- 上下文长度未公开:官方未披露具体上下文长度参数,导致在超长文本任务中难以评估极限能力,未来版本可能进一步开放相关数据
- Token消耗增加:由于新tokenizer机制,同一输入可能产生1.0-1.35倍token消耗,据官方说明需通过参数优化降低成本
- 安全限制较严格:模型对部分请求自动阻断,尤其在安全与网络领域,可能影响部分专业用户使用,官方提供验证计划解决此问题
Claude Opus 4.7相关资源
Claude Opus 4.7的典型应用场景
- 软件开发:输入项目需求文档,模型生成代码与架构设计,提升开发效率并减少人工成本
- 金融分析:输入财务数据,生成分析报告与预测模型,辅助决策制定
- 文档处理:输入长文本资料,输出摘要与关键结论,提高信息处理效率
- 多模态分析:输入图像与文本,生成结构化数据,适用于数据分析与视觉识别
- 企业自动化:通过API接入业务系统,实现自动化流程与智能决策支持
Claude Opus 4.7常见问题
Claude Opus 4.7怎么用?
Claude Opus 4.7通过Anthropic平台或API调用使用,用户需获取API Key并调用claude-opus-4-7模型。
Claude Opus 4.7如何计费?
Claude Opus 4.7采用按token计费模式,输入约$5/百万tokens,输出约$25/百万tokens。
Claude Opus 4.7和GPT-5哪个好?
Claude Opus 4.7在代码生成与长任务一致性方面表现较强,而GPT-5在多模态与生态方面更完善。建议根据具体应用场景选择,如开发优先Claude,多模态优先GPT。
Claude Opus 4.7支持多模态吗?
Claude Opus 4.7支持图像与文本输入,且支持高分辨率图像处理。
Claude Opus 4.7有免费额度吗?
官方未明确提供免费额度,主要通过API商业化使用。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。

相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号