Sage快速摘要:端侧智能体模型能力与应用场景
Sage是商汤绝影于2026年4月发布的端侧多模态智能体基座大模型,支持复杂任务推理、工具调用与车端部署,适用于智能座舱和端侧Agent场景。
- 模型名称:Sage
- 开发公司:商汤绝影
- 发布时间:2026年4月
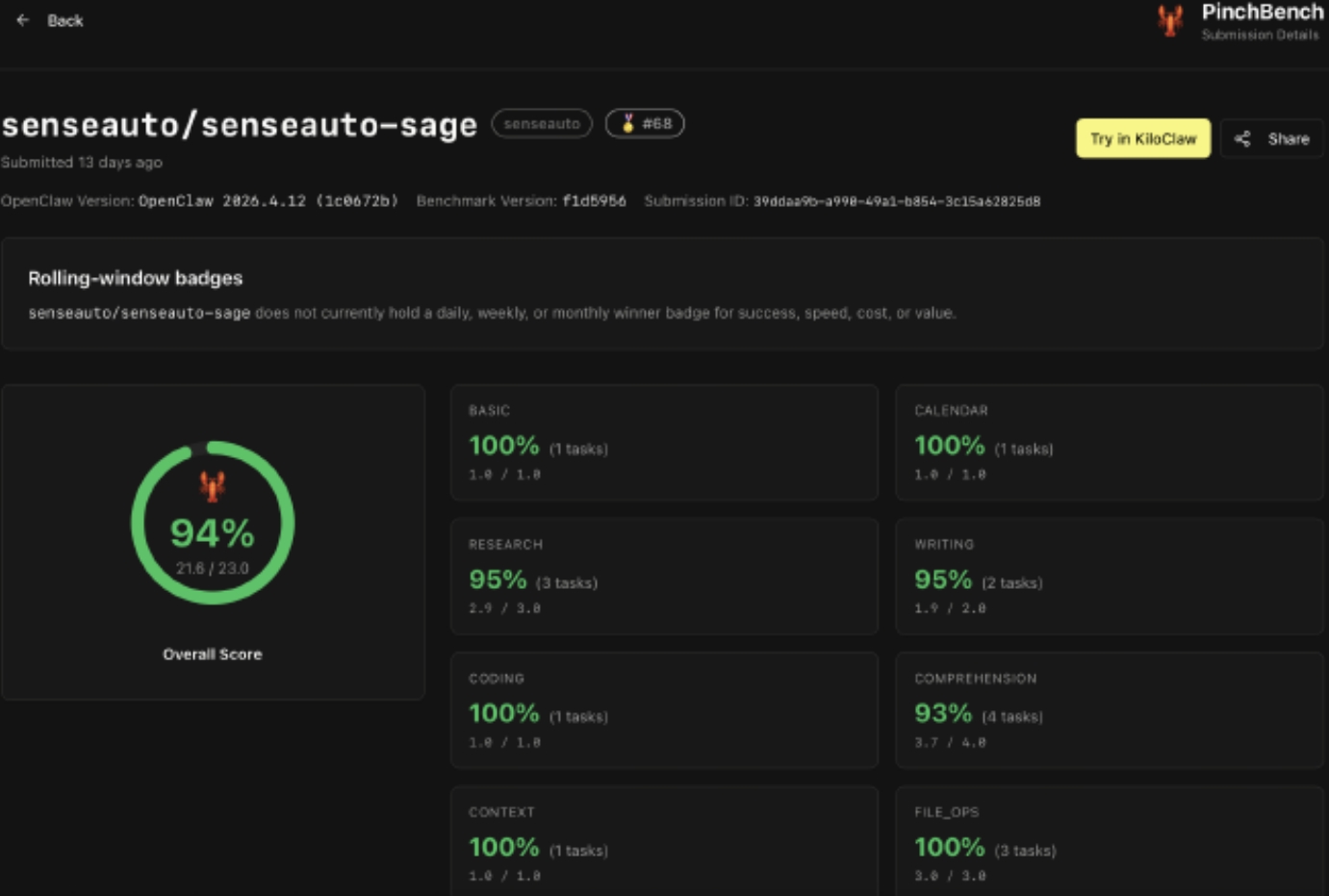
- 主要功能:支持复杂推理、工具调用、多模态感知、环境理解与端侧执行,PinchBench任务完成率94%。
- 使用要求:当前主要面向英伟达Orin X部署及车载智能体开发使用,并非面向普通消费者独立注册产品。
- 开源情况:截至目前官方未明确宣布Sage开源计划,据公开资料主要以量产部署和生态接入为主。
- 技术特点:SCOUT与ERL构成关键后训练体系,复杂任务完成率提升20%,训练GPU小时节省约60%。
- 性能指标:TTFT约0.5秒,TPOT约0.03秒,吞吐约80 tk/s,体现端侧低延迟推理能力。
- 价格信息:目前无公开API价格与商业计费表,官方资料未明确免费额度或开放调用价格。
Sage的核心优势
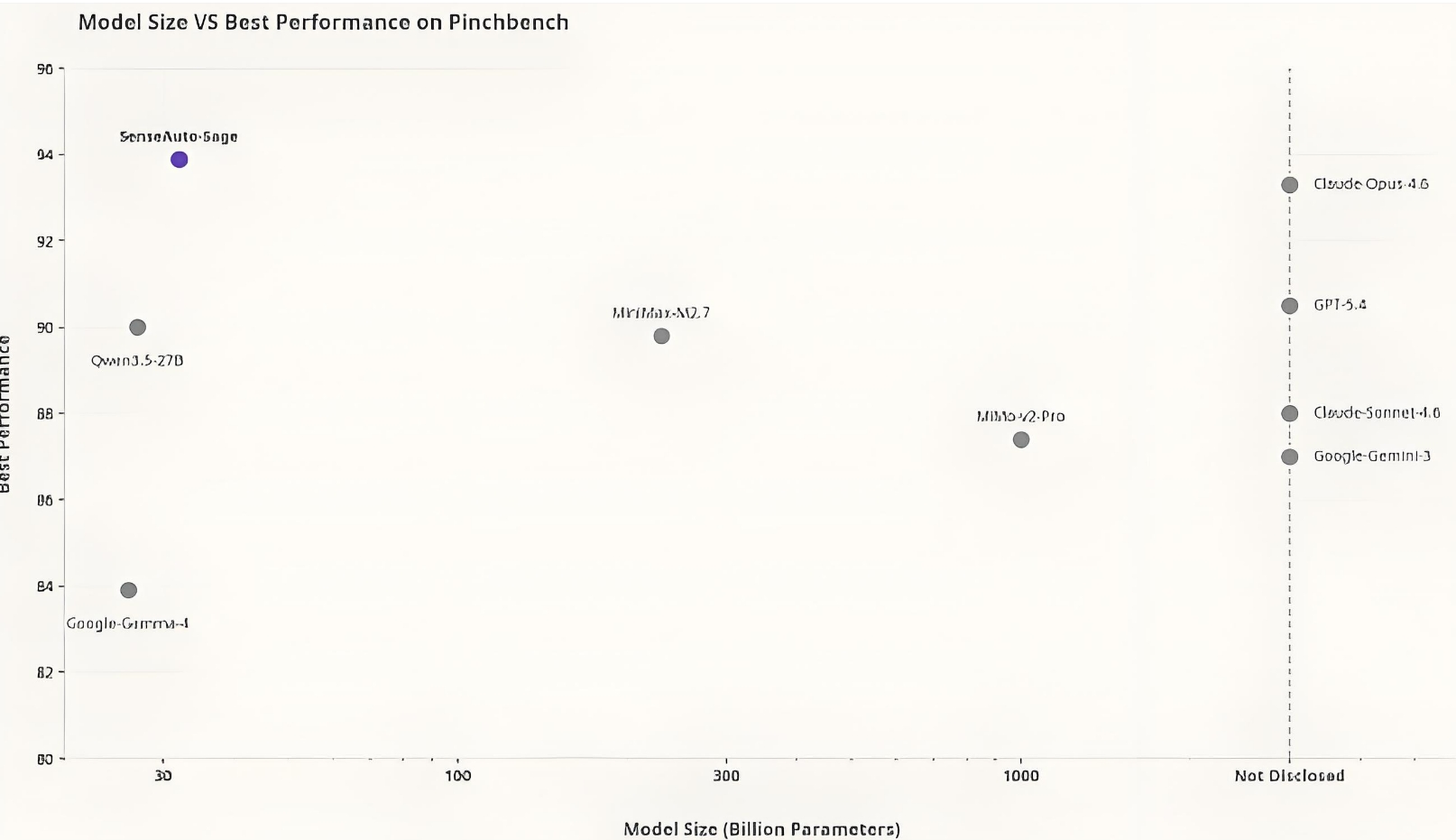
- 端侧Agent执行优势:Sage采用MoE小激活参数路线,以3B激活规模实现94%任务完成率,据PinchBench测试数据高于多款云侧模型,体现端侧推理效率与任务闭环执行能力的平衡。
- 低算力部署优势:相较42B激活参数的MiMo-v2-Pro,Sage激活算力需求约为其1/14,显存估算约1/31,在车端有限资源下具备更高部署可行性,据公开测试显示。
- 复杂推理稳定性:ERL通过错误步骤擦除与重生成机制减少链式推理偏差扩散,据ICLR 2026收录成果,复杂任务成功率提升20%,强化Agent连续任务稳定执行。
- 训练效率优化:SCOUT分级协同学习框架先由轻量模型探路,再由大模型吸收经验,据公开论文可节省约60% GPU小时,并提升复杂场景技能学习效率。
- 多模态场景融合:Sage不仅支持语言推理,还结合环境感知、视觉语义与工具调用,在Human Semantic Understanding测试达91分,据测试数据体现座舱多模态理解能力。
Sage的核心功能
- 复杂任务工具调用:模型支持长链路任务拆解与工具调用,例如输入多步骤导航与车控复合指令,可输出动作链闭环执行,在τ2-bench得分80,据测试数据表明任务执行能力突出。
- 多模态座舱理解:输入乘员状态、语音命令和视觉环境信息,模型可联动车载系统输出路线调整、儿童模式等结果,场景推理精度超过90%,据公开数据披露。
- 高效端侧推理:部署于Orin X平台时,模型首字响应约0.5秒,单Token延迟0.03秒,支持实时交互级体验,并降低依赖云侧推理成本。
- Agent框架接入:作为基座模型支持接入OpenClaw、Hermes等框架,开发者可输入工具链配置和任务模板,实现端侧Agent编排与自动执行。
- 专业知识与推理:在MMLU Pro获76分、GPQA Diamond获77分,支持复杂知识推理输入与多跳任务处理,对研究级逻辑任务具备一定适配能力。
Sage的技术原理
- MoE模型架构:采用32B总参数与3B激活参数MoE结构,通过专家路由机制降低推理负载,在端侧算力约束下兼顾性能和延迟。
- SCOUT训练机制:技术路径采用小模型任务探索与大模型知识吸收双阶段训练机制,提升复杂任务泛化能力,同时降低训练资源消耗。
- ERL推理机制:模型在推理过程中支持错误步骤识别、擦除与重生成,相比传统强化学习减少错误传播,增强长链推理稳定性。
- 多模态原生训练:训练结合语义、视觉和环境状态原生数据,支持舱驾场景输入融合,而不仅依赖单纯文本监督训练路径。
- 端侧推理优化:结合Orin X硬件推理优化实现80 tk/s吞吐,并在低延迟条件下维持复杂任务执行,这也是端侧智能体路线的重要实现基础。
Sage与主流模型对比
| 对比维度 | Sage | Claude Opus 4.6 | Gemma 4 | MiMo-v2-Pro |
|---|---|---|---|---|
| PinchBench任务完成率 | 94% | 93.3% | 83.9% | 87.4% |
| 激活参数 | 3B | 未披露 | 高于3B | 42B |
| MMLU Pro | 76 | 高 | 约低10% | 未披露 |
| 端侧部署 | 支持 | 不以端侧为主 | 支持 | 支持 |
| 工具调用闭环 | 强 | 强 | 中 | 中 |
| 多模态座舱适配 | 原生支持 | 通用型 | 通用型 | 端侧支持 |
据PinchBench与公开基准测试数据,Sage在任务完成率上表现突出,但技术路径与通用大语言模型不同,更偏端侧智能体基座。与Claude Opus 4.6相比,差异主要不在纯语言能力,而在部署目标和成本结构;与Gemma 4相比,Sage在τ2-bench和场景推理指标优势更多来自后训练机制优化;与MiMo-v2-Pro对比,性能差异主要源于激活参数效率和训练路线,而不是单纯模型规模。对比说明Sage更适合车载Agent执行场景,而非通用聊天模型替代。
如何使用Sage
- 部署环境配置:在Orin X或兼容端侧环境配置推理环境,设置模型加载参数和显存预算,例如激活推理资源按3B专家路由模式配置,可优化延迟表现。
- 接入Agent框架:通过OpenClaw或Hermes接入任务编排层,设置工具调用链、函数接口和任务模板,例如配置导航、影音和车控联动链路。
- 输入任务指令:通过复合指令输入多步骤任务,如路线规划加设备联动,调优任务拆解深度与工具调用轮数,可提升任务成功率。
- 推理性能调优:根据TPOT和吞吐指标调整并发、缓存和上下文配置,例如控制任务上下文长度与工具调用频率优化端侧响应速度。
- 场景效果验证:通过PinchBench类任务集或自定义场景集测试输出效果,对复杂任务成功率、延迟和错误纠偏能力进行验证。
Sage的相关资源
商汤绝影官方地址:https://www.sensetime.com/cn/product-business?categoryId=32857
Sage的局限性
- 生态开放限制:当前主要面向车端量产和合作生态,公开API能力与开发者开放程度有限,据官方公开资料未明确通用开放调用计划。
- 通用模型覆盖限制:Sage优势集中在Agent任务与车端场景,在开放域聊天、广泛创作类任务上公开数据有限,通用能力边界仍需更多验证。
- 硬件依赖限制:性能数据主要基于Orin X平台,跨硬件迁移效果可能存在差异,据技术路径推测不同算力平台延迟表现可能变化。
Sage的典型应用场景
- 智能座舱控制:输入复合车控指令,模型解析并调度空调、影音与导航系统,输出自动执行结果,提升座舱交互效率与任务闭环能力。
- 主动场景服务:输入环境状态与乘员状态数据,模型结合规则推理触发儿童模式或路线调整,输出主动服务响应。
- 端侧Agent助手:输入复杂任务目标,结合工具链执行研究、文件处理或日程任务,输出闭环任务结果,适用于Agent实验环境。
- 舱驾融合方案:输入驾驶状态、传感器数据和用户意图,模型执行场景联动输出综合决策支持,用于舱驾一体开发。
- 低延迟边缘部署:输入端侧任务请求,在低网络依赖条件完成本地推理输出,适用于高实时要求边缘智能场景。
Sage常见问题
Sage怎么用?
Sage当前主要通过车端部署和Agent框架接入使用,不是面向普通用户网页注册工具。开发流程通常包括模型部署、工具链配置和任务调优,建议结合Orin X及OpenClaw生态验证效果,并关注上下文配置和延迟控制。
Sage如何计费?
官方目前未公开独立API价格或Token计费方案,现阶段更偏生态集成模式。
Sage和Claude Opus 4.6哪个好?
根据PinchBench测试,Sage任务完成率略高,但两者定位不同。Claude偏通用云端大模型,Sage偏端侧智能体执行。如果侧重车端部署与低延迟任务闭环,Sage更适合;如果偏通用对话与云端推理,Claude更均衡。
Sage支持实时推理吗?
在Orin X平台TTFT约0.5秒、TPOT约0.03秒,据公开数据具备实时交互级能力,但其核心定位是任务执行型智能体而非传统流式对话模型,实际表现仍依赖硬件算力与部署环境。
Sage有免费额度吗?
目前官方未披露免费额度,也未提供公开API试用计划。产品定位主要面向车端与企业生态集成,未来是否开放开发者免费测试入口需关注官方后续发布信息。

 浙公网安备33010202004812号
浙公网安备33010202004812号