LPM 1.0快速摘要:视频生成与对话交互场景
LPM 1.0是Anuttacon团队于2026年4月11发布的视频生成模型,支持多模态对话视频生成与实时交互,适用于虚拟人、直播与游戏场景。
- 模型名称:LPM 1.0(Large Performance Model)
- 开发公司:Anuttacon(蔡浩宇AI公司)
- 发布时间:2026年4月11日发布,据arXiv论文2604.07823v1公开信息显示
- 主要功能:支持对话视频生成、语音驱动动画、身份一致性视频生成与长时序视频输出
- 使用要求:需输入人物图像、语音或文本提示,结合多模态输入进行生成
- 开源情况:当前未明确完全开源
- 适用场景:适用于虚拟主播、数字人交互、游戏NPC与视频内容生成等场景
- 技术特点:基于17B参数Diffusion Transformer与多模态对齐机制,据官方模型架构描述
- 价格:目前未公布API价格或商业定价,主要以研究模型形式发布
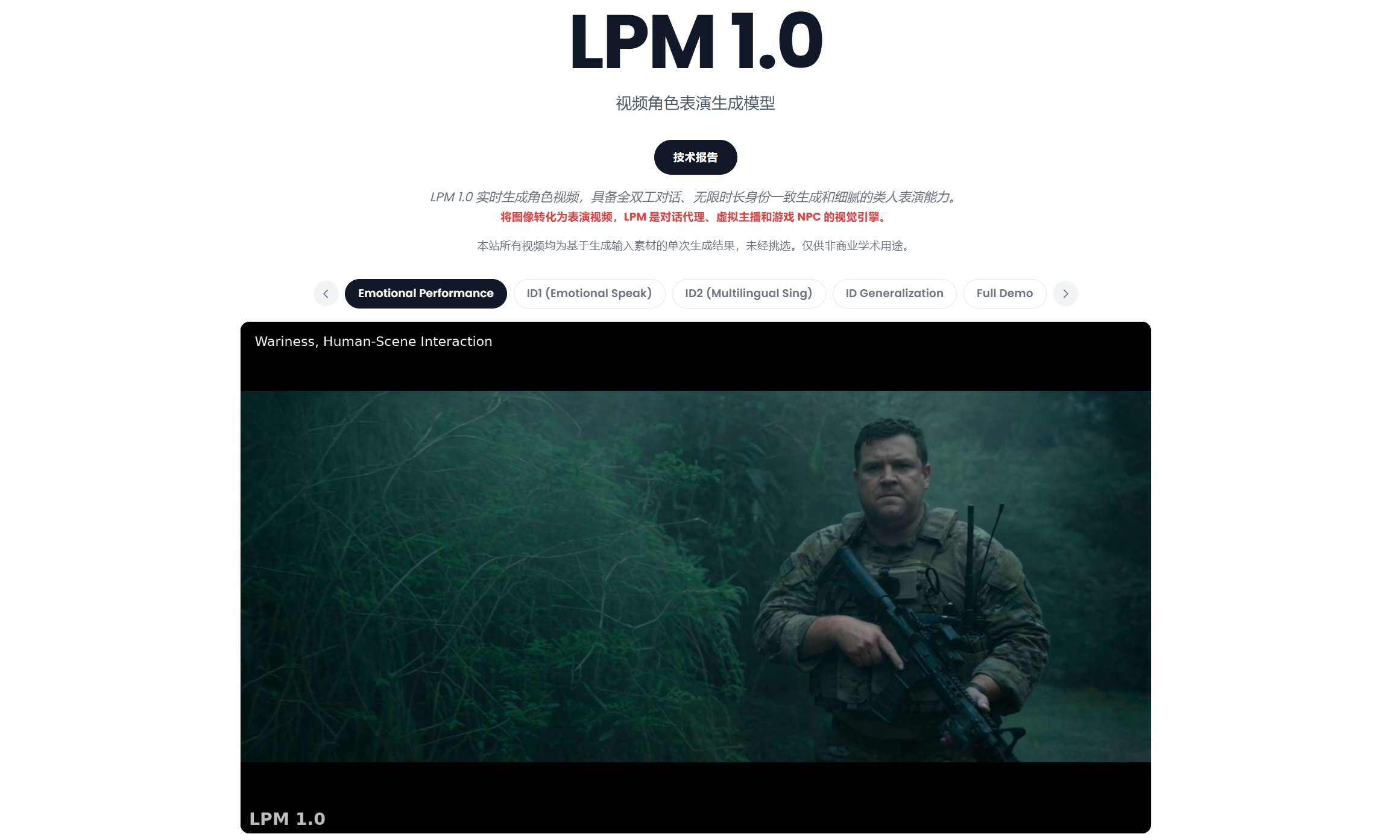
LPM 1.0的核心优势
- 身份一致性增强:通过多参考图像与身份感知机制实现人物外观稳定,避免视频生成中常见的人脸漂移问题,据LPM-Bench测试身份一致性偏好达58.5%,在长视频中仍保持稳定视觉效果
- 多模态控制能力:结合语音、文本与图像多模态输入,通过跨模态注意力机制实现动作与情绪控制,据测试文本控制能力偏好达55.7%,支持复杂动作描述与情绪表达
- 实时生成能力:通过Online LPM蒸馏架构实现流式推理,每秒生成24帧视频,单chunk延迟约0.35秒,据系统优化数据说明,适用于实时交互场景
- 长时序稳定性:采用chunk连续生成与缓存机制实现长时间视频输出,支持分钟级甚至更长视频生成,据官方说明可达10分钟以上稳定输出
- 整体真实感提升:在人类评测中整体偏好率达64.3%优于Kling-Avatar-2,据LPM-Bench测试数据表明,在动作自然度与情绪表达方面表现更稳定
LPM 1.0的核心功能
- 语音驱动视频生成:通过语音输入驱动人物口型与动作生成,例如输入10秒语音即可生成同步视频,支持情绪语音表达,据测试音视频同步评分达4.13以上
- 文本控制动作:输入文本描述如“转头微笑并挥手”,模型可生成对应动作视频,结合文本编码器实现精细控制,据测试文本控制评分达4.32
- 听觉响应生成:模型支持“听”模式,根据用户语音生成自然点头、表情变化等反应,据Listen场景评分达4.51,表现出较强情绪理解能力
- 对话视频生成:支持说话与倾听双模式切换,实现完整对话视频生成,输入多轮语音即可输出连续互动视频,据对话测试评分3.90以上
- 长视频连续生成:通过chunk拼接与latent延续机制实现长视频生成,例如输入多段音频生成10分钟连续视频,保持动作与身份一致
LPM 1.0的技术原理
- Diffusion Transformer架构:基于17B参数双向扩散Transformer模型,结合图像视频生成能力与Transformer结构,实现高质量视频生成,据模型架构说明
- 多模态训练机制:训练数据包含语音、视频与文本,通过跨模态对齐学习行为模式,据数据构建描述包含数万视频与1.7万亿token
- 双流音频建模:分别建模说话与倾听音频流,实现角色交互行为生成,例如同时输入语音与文本控制动作与情绪
- 自回归蒸馏机制:通过DMD蒸馏方法将Base模型转换为Online模型,实现低延迟推理,据训练阶段分为4阶段优化
- 流式推理架构:采用Generator+Refiner结构分阶段生成视频,结合缓存机制实现连续视频输出,支持无限长度生成
LPM 1.0与主流模型对比
| 对比维度 | LPM 1.0 | Kling-Avatar-2 | OmniHuman-1.5 |
| 身份一致性 | 58.5%偏好率 | 较低,存在漂移 | 中等,存在变化 |
| 视频长度 | 无限时长 | 约30秒 | 约30秒 |
| 多模态能力 | 语音+文本+图像 | 有限 | 支持但较弱 |
| 实时能力 | 支持流式生成 | 不支持 | 有限支持 |
| 控制能力 | 文本精细控制 | 较弱 | 中等 |
从对比结果来看,LPM 1.0在身份一致性与长视频生成方面优势明显,据LPM-Bench测试数据显示其在多个维度均优于对比模型。性能差异主要来源于模型参数规模(17B)与多模态训练数据规模更大,同时采用扩散Transformer结构增强生成质量。相比之下,Kling与OmniHuman在视频长度与控制精度上存在限制,主要由于其架构未针对长序列与对话交互进行优化。
如何使用LPM 1.0
- 准备输入数据:上传人物图像并提供参考图片,同时准备语音或文本输入,例如10秒语音与动作描述文本,以确保生成效果更稳定
- 配置多模态输入:设置语音流(说话或倾听模式)与文本提示参数,如情绪标签或动作关键词,提高生成精度与控制能力
- 调用生成模型:输入多模态数据并启动生成流程,模型将按chunk逐步生成视频,默认每秒24帧输出,确保流畅播放
- 优化输出效果:调整文本提示与语音节奏,例如增加情绪描述或动作细节,可显著提升表现力与自然度
LPM 1.0的局限性
- 单角色限制:当前主要支持单人物生成,多角色互动能力有限,据论文说明仍未支持复杂多人场景,未来计划扩展多角色交互
- 场景理解不足:对复杂环境与物理交互支持较弱,例如动态场景变化处理能力有限,据论文未来工作部分提及改进方向
- 长对话记忆有限:虽然支持长视频生成,但缺乏长期语义记忆能力,无法维持复杂剧情连续性,未来需引入长期记忆机制
LPM 1.0相关资源
- 项目官网:https://large-performance-model.github.io/
- arXiv技术论文:https://arxiv.org/pdf/2604.07823
LPM 1.0的典型应用场景
- 虚拟主播:输入人物形象与语音,生成直播视频,实现实时互动与表达,提高直播自动化水平
- 数字人客服:输入客户语音与脚本,生成实时回应视频,提高客服交互体验与情绪表达能力
- 游戏NPC:根据玩家语音生成NPC反应视频,实现沉浸式互动体验,提高游戏真实感
- 视频内容生成:输入脚本与语音生成短视频内容,适用于内容创作者自动化生产视频
- 教育培训:生成讲解视频与虚拟教师互动,提高在线教育的沉浸感与理解效果
LPM 1.0常见问题
LPM 1.0怎么用?
LPM 1.0需要输入人物图像、语音或文本提示,通过多模态模型生成视频内容。建议先使用短语音测试效果,再逐步增加视频长度,注意输入质量会直接影响输出效果。
LPM 1.0如何计费?
当前未公布官方API价格,主要以研究模型发布。建议关注后续商业化发布信息,实际使用可能按生成时长或计算资源计费。
LPM 1.0和OmniHuman哪个好?
根据LPM-Bench测试,LPM 1.0在身份一致性与控制能力上更优,而OmniHuman在部分场景下表现稳定。建议高精度视频生成选择LPM。
LPM 1.0支持实时生成吗?
支持,通过Online LPM实现流式推理,每秒约24帧输出。建议在实时交互场景中使用优化版本以降低延迟。
LPM 1.0有免费额度吗?
当前未明确提供免费额度。建议关注官方发布或研究版本资源,使用前确认是否需要付费或申请权限。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。
相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号