GLM-5.1-highspeed快速摘要
GLM-5.1-highspeed是智谱 Z.ai 推出的高速推理大语言模型,属于 GLM-5.1 旗舰模型的高速版本。该模型通过推理引擎、调度系统与底层基础设施的系统级优化,实现最高 400 tokens/s 的输出速度,适用于低延迟 AI 编程、实时交互与企业级智能体场景。
- 模型名称:GLM-5.1-highspeed(GLM-5.1 高速版)
- 发布时间:2026年5月22日
- 模型关系:GLM-5.1-highspeed 是 GLM-5.1 旗舰模型的高速版本,完整保留旗舰模型能力,并重点优化低延迟推理。
- 核心特点:支持最高400 tokens/s输出速度,并支持思考模式、流式输出、Function Call、MCP与结构化输出。
- 上下文能力:支持200K上下文窗口,最大输出128K Tokens。
- 适用场景:适用于AI编程、实时语音、企业级Agent、商业决策与高并发API场景。
- 开放方式:目前仅面向智谱 BigModel 平台部分企业客户定向开放。
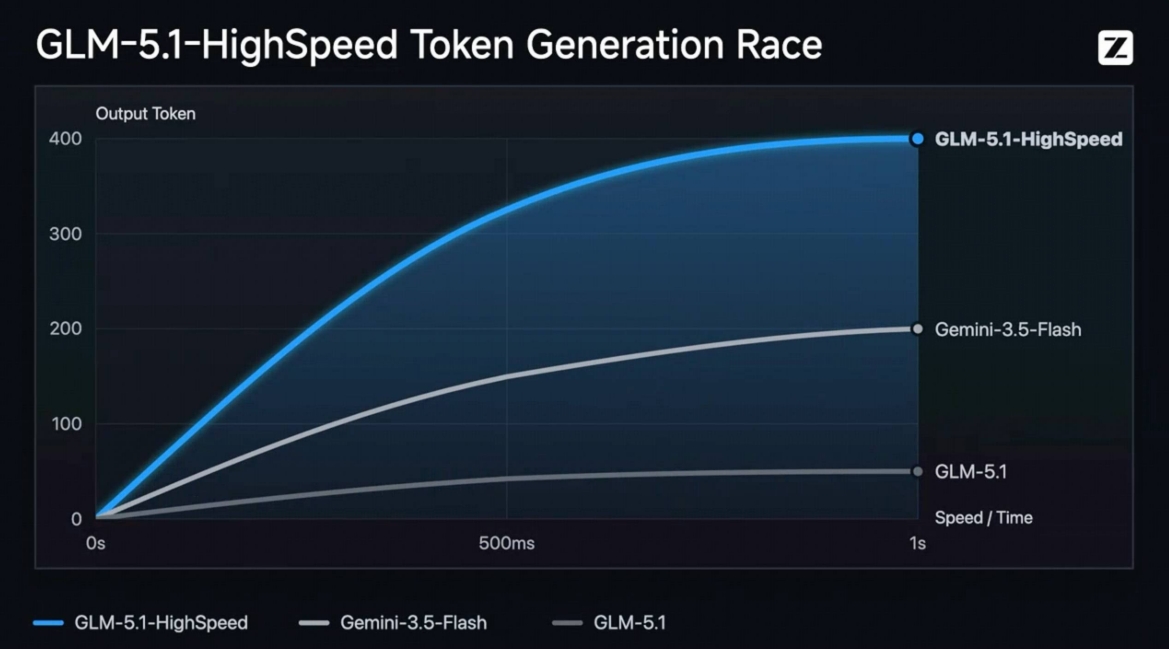
GLM-5.1-highspeed的核心优势
- 400 tokens/s高速输出:据官方资料显示,GLM-5.1-highspeed输出速度最高达到400 tokens/s,刷新当前主流大模型API速度上限。
- 旗舰能力完整保留:GLM-5.1-highspeed并非轻量模型,而是在完整保留GLM-5.1旗舰能力基础上进行高速优化,依然支持复杂推理与大型工程任务。
- 低延迟实时交互:模型重点优化实时响应能力,可用于实时UI生成、动态内容反馈与连续交互场景。
- 企业级高并发优化:模型通过动态批处理、请求合并与KV缓存调度优化,在高并发场景下可持续保持低尾延迟。
- AI编程能力强化:GLM-5.1-highspeed针对Coding Agent、多轮代码生成与大型工程重构场景进行优化,可明显降低长链路任务等待时间。
- Agent生态支持:支持Function Call、MCP与结构化输出能力,适合企业智能体平台集成与自动化任务执行。
GLM-5.1-highspeed的核心功能
- 思考模式:支持多种Thinking思考模式,可根据不同任务需求调整推理深度,适用于复杂分析与代码推理场景。
- 流式输出:支持实时流式响应,模型可边生成边返回结果,提升实时交互与语音助手体验。
- Function Call工具调用:支持外部工具调用能力,可与数据库、搜索系统与企业工具链集成。
- 结构化输出:支持JSON等结构化格式输出,方便企业系统与自动化平台直接解析结果。
- 上下文缓存:支持上下文缓存机制,可优化长对话与大型Agent任务的推理效率。
- MCP扩展支持:模型支持MCP工具协议,可灵活调用外部工具与数据源。
GLM-5.1-highspeed的技术原理
- TileRT推理优化:GLM-5.1-highspeed由智谱GLM团队与TileRT团队联合打造,针对GLM-5.1架构重写核心推理路径,提高单卡吞吐能力。
- 动态批处理调度:通过动态批处理、请求合并与KV缓存调度优化,可降低高并发场景下的尾延迟问题。
- 基础设施协同优化:模型围绕推理集群、网络链路与负载均衡进行协同优化,确保400 tokens/s能够稳定运行于生产环境。
- 长上下文能力:GLM-5.1-highspeed支持200K上下文窗口,可持续处理大型工程代码与复杂Agent链路任务。
- 高速推理架构:模型核心目标是同时兼顾旗舰级能力与极低延迟,解决传统大模型“速度与质量难兼得”的问题。
GLM-5.1-highspeed与主流模型对比
| 对比维度 | GLM-5.1-highspeed | Claude Opus 4.7 | Gemini 3.1 Pro | DeepSeek-V4 |
|---|---|---|---|---|
| 模型定位 | 高速旗舰推理模型 | 复杂推理模型 | 多模态旗舰模型 | 通用推理模型 |
| 输出速度 | 400 tokens/s | 官方未公开 | 官方未公开 | 官方未公开 |
| 上下文窗口 | 200K | 长上下文 | 超长上下文 | 长上下文 |
| AI编程能力 | 高 | 高 | 中高 | 高 |
| 实时交互能力 | 极强 | 中 | 中高 | 中 |
| 工具调用支持 | Function Call + MCP | 工具调用 | Google生态 | 开放工具生态 |
GLM-5.1-highspeed的核心优势在于“旗舰能力+极低延迟”组合。相比Claude Opus 4.7,其更强调实时Agent与AI编程效率;Gemini 3.1 Pro更偏向多模态与Google生态整合;DeepSeek-V4则更偏向开放部署与成本优化。对于高频实时交互场景,GLM-5.1-highspeed更适合企业级生产环境。
如何使用GLM-5.1-highspeed
- 申请API访问权限:开发者需先进入智谱 BigModel 开放平台提交企业接入申请,审核通过后可获得 GLM-5.1-highspeed 的API调用资格与专属API Key。
- 安装开发SDK:Python用户可通过pip安装zai-sdk或zhipuai SDK,Java开发者则可通过Maven方式引入官方依赖库。
- 初始化客户端:完成SDK安装后,需使用API Key创建ZhipuAiClient或ZhipuAI客户端实例。
- 配置模型参数:调用接口时需指定模型名称为“glm-5.1-highspeed”,并根据业务需求开启thinking推理模式或流式输出功能。
- 发送推理请求:开发者可通过chat.completions.create接口提交消息列表,并获取模型返回结果。
GLM-5.1-highspeed的局限性
- 开放范围有限:目前GLM-5.1-highspeed仅向部分企业客户开放,普通个人开发者暂无法直接申请。
- 暂未公开完整价格:截至2026年5月,官方尚未公布完整API价格体系。
- 主要面向云端部署:GLM-5.1-highspeed重点优化企业级云推理场景,官方暂未提供完整本地离线部署方案。
GLM-5.1-highspeed相关资源
GLM-5.1-highspeed的典型应用场景
- AI编程平台:适用于Coding Agent、多轮代码生成与大型工程重构,可明显降低复杂任务等待时间。
- 实时交互系统:支持游戏生成、动态UI构建与实时内容反馈场景。
- 商业决策分析:适用于实时数据分析、运营问答与多Agent协同决策场景。
- 实时语音助手:适用于语音客服、AI陪练与会议助手等低延迟语音交互场景。
- 智能Agent平台:支持长链路任务执行与外部工具调用,可用于自动化办公与企业智能体系统。
GLM-5.1-highspeed常见问题
GLM-5.1-highspeed怎么用?
GLM-5.1-highspeed目前通过智谱 MaaS 平台API调用使用,用户需申请接口权限并配置API Key后才能正式调用。
GLM-5.1-highspeed如何计费?
截至2026年5月,官方尚未公开完整API价格体系。目前同类企业大模型API通常采用Token按量计费模式。
GLM-5.1-highspeed和DeepSeek-V4速度对比如何?
据2026年5月官方数据显示,GLM-5.1-highspeed输出速度最高达到400 tokens/s,更适合低延迟实时推理场景。
GLM-5.1-highspeed适合哪些行业?
GLM-5.1-highspeed适用于AI编程、实时客服、商业分析与智能Agent行业场景,尤其适合高并发企业系统。
GLM-5.1-highspeed有免费额度吗?
官方目前未明确公布免费额度政策,高速版主要面向企业客户开放,开发者需关注官方测试活动。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。
相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号