Baichuan-M4快速摘要
Baichuan-M4是百川智能联合清华大学THUBPM团队研发的医疗大模型(LLM),支持连续医疗照护、循证医学检索、多模态医疗理解和长期患者管理,适用于智能问诊、辅助诊疗、医学研究和慢病随访等场景。
- 模型名称:Baichuan-M4
- 开发公司:百川智能(Baichuan Intelligence)
- 联合研发:清华大学THUBPM团队
- 发布时间:2026年6月
- 模型类型:医疗大模型(Medical Large Language Model)
- 主要功能:医疗问诊、循证医学检索、长期患者管理、医学OCR、医学影像理解
- 技术架构:Baichuan-Harness医疗智能体运行框架
- 核心能力:长期记忆、多Agent协作、多模态医疗推理
- 适用场景:医院辅助决策、慢病管理、健康咨询、医学研究
- 多模态支持:医疗文档、胸部X光、皮肤病图像
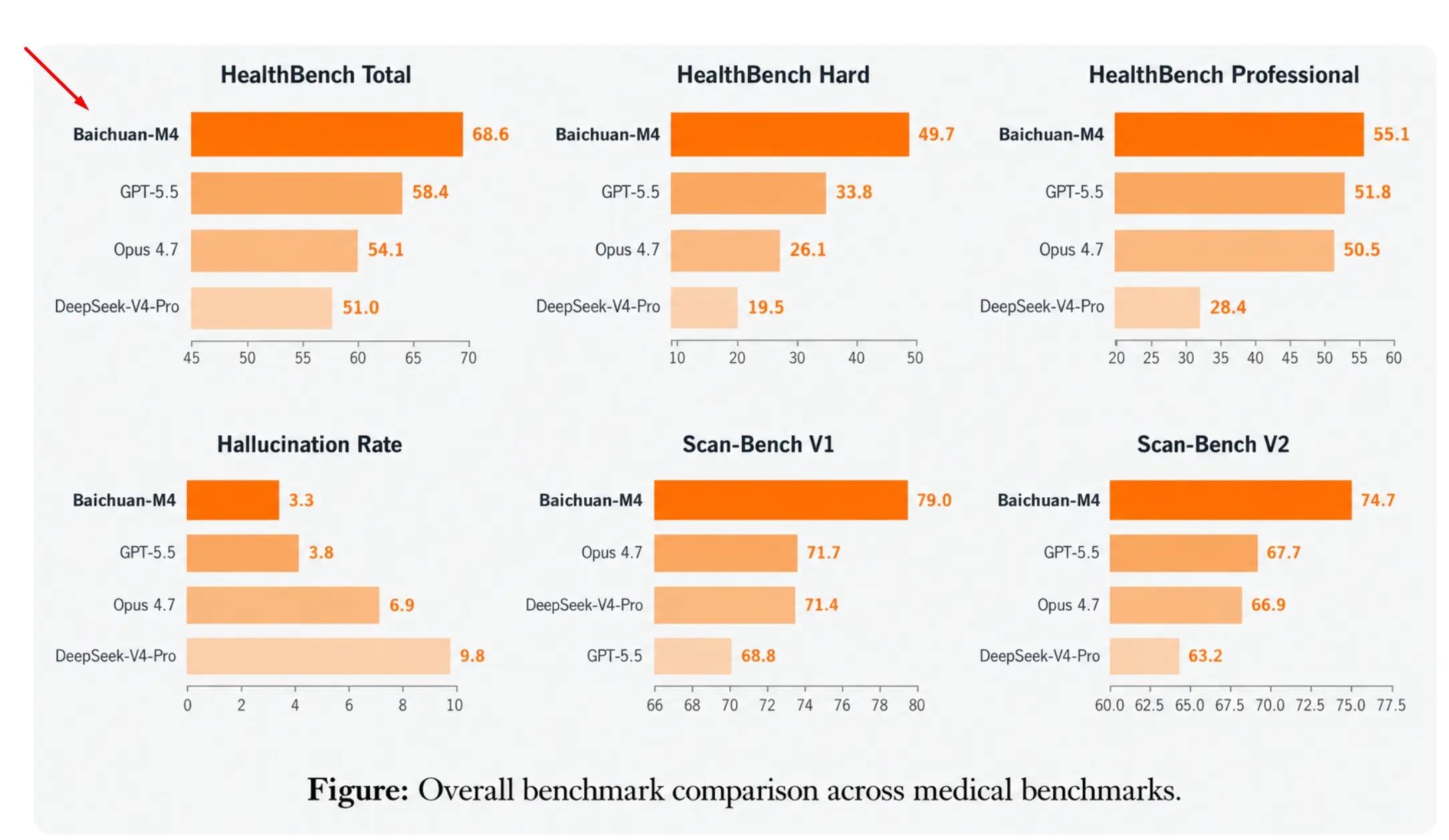
- HealthBench成绩:68.6分,据2026年官方技术报告显示
- 幻觉率:3.3%,据HealthBench测试数据显示
- 循证检索能力:Citation Precision达到90.0,据Baichuan-EBM评测数据显示
Baichuan-M4的核心优势
- 医疗推理能力突出:Baichuan-M4围绕真实医疗决策场景进行专项训练,通过医疗强化学习与临床推理优化机制提升复杂问题分析能力。据HealthBench测试数据显示,其总分达到68.6,在公开医疗模型评测中表现突出。
- 长期患者记忆机制:模型引入长期患者记忆系统,可持续记录既往病史、检查结果、药物反馈及复诊信息。据官方测试数据显示,其长程临床记忆能力达到86.9分,适合慢病管理和长期随访场景。
- 循证医学检索能力:模型支持自动检索临床指南、Meta分析和医学文献,并将证据整合到回答过程中。据Baichuan-EBM测试数据显示,Citation Precision达到90.0,可有效提升医疗回答可信度。
- 低幻觉率设计:通过SPAR++强化学习框架和医疗行为约束机制降低错误信息生成概率。据官方HealthBench测试数据显示,Baichuan-M4幻觉率仅为3.3%,低于多数通用大模型在医疗场景中的表现。
- 医疗多模态能力:除文本理解外,模型支持医学文档解析、胸部X光分析和皮肤病图像理解。据官方评测数据显示,其IU-Xray与f17k等医学视觉任务均达到当前医疗模型较高水平。
Baichuan-M4的核心功能
- 智能医疗问诊:输入患者症状后,模型能够主动进行病史采集和风险筛查。例如输入“持续胸闷两周”,系统可进一步追问既往疾病、持续时间及伴随症状,并生成结构化问诊记录。
- 循证医学问答:模型能够自动检索权威医学指南和临床研究。例如输入“糖尿病患者是否适合使用某类药物”,系统会返回相关研究依据、指南建议及证据来源说明。
- 长期健康管理:支持持续记录患者健康数据和随访结果。例如高血压患者连续上传血压记录后,系统能够分析变化趋势并生成阶段性健康管理建议。
- 医疗文档解析:支持病历、检验报告、处方单和出院记录识别。例如上传血常规报告后,模型能够自动提取异常指标并生成结构化医学摘要。
- 医学影像辅助分析:支持胸部X光和皮肤病图像理解。例如上传胸片后可自动生成Findings与Impression报告,为医学影像分析提供辅助支持。
Baichuan-M4的技术原理
- Baichuan-Harness架构:模型采用统一运行框架连接训练与推理环境,实现长期记忆管理、工具调用和医疗任务调度能力统一管理,提高复杂医疗场景稳定性。
- SPAR++强化学习:通过Span-Level Reward机制对医疗推理过程进行细粒度优化,不仅关注最终答案正确性,还关注病史采集和临床分析过程合理性。
- 课程式强化学习:训练阶段按照首诊、复诊、随访和长期管理逐步增加任务难度,使模型逐步掌握连续医疗照护环境下的信息处理能力。
- 推理路径压缩:采用Reasoning Path Compression技术优化推理链结构。据官方技术报告显示,该技术可显著降低推理成本,同时保持复杂医疗推理质量。
- 多工具协同机制:模型集成长期记忆模块、医学检索引擎、OCR系统和视觉理解模型,实现文本、图像和结构化医疗数据联合推理。
Baichuan-M4与主流模型对比
| 对比维度 | Baichuan-M4 | GPT-5.5 | DeepSeek-V4-Pro | Qwen3.5 |
|---|---|---|---|---|
| 模型定位 | 医疗大模型 | 通用大模型 | 通用大模型 | 通用大模型 |
| HealthBench总分 | 68.6 | 58.4 | 51.0 | 未公布 |
| HealthBench Hard | 49.7 | 33.8 | 19.5 | 未公布 |
| 幻觉率 | 3.3% | 3.8% | 9.8% | 未公布 |
| 长程临床记忆 | 86.9 | 81.7 | 81.2 | 未公布 |
| 循证医学检索 | 83.1 | 79.2 | 未公布 | 60.4 |
| 医疗OCR | 0.914 | 未公布 | 未公布 | 0.871 |
| 医学影像理解 | 支持 | 支持 | 支持 | 支持 |
从定位来看,Baichuan-M4属于专门面向医疗领域训练的垂直大模型,而GPT-5.5、DeepSeek-V4-Pro和Qwen3.5属于通用大模型。在HealthBench系列医疗评测中,Baichuan-M4取得68.6分和49.7分的成绩,明显高于多数通用模型。其优势主要来自医疗专项强化学习、长期患者记忆系统和循证医学检索机制。幻觉率控制在3.3%,也体现出医疗场景专项优化效果。对于医疗问诊、医学研究和慢病管理等专业场景,Baichuan-M4具有更强针对性;而通用模型则在跨领域知识覆盖方面更具优势。
如何使用Baichuan-M4
- 获取模型服务:通过百川智能官方平台或合作医疗机构接入模型服务,完成账号认证和权限配置后即可开始测试相关能力。
- 上传医疗数据:支持上传病历、检验报告、医学影像和健康记录。建议保证图像清晰度和文档完整性,以提升识别准确率。
- 输入医疗问题:可直接输入疾病咨询、药物问题或医学研究问题,也可结合患者历史资料进行连续分析和风险评估。
- 查看生成结果:系统会返回诊疗建议、文献依据、风险提示或结构化医学摘要,并自动关联相关医学证据来源。
- 人工复核结果:对于诊断建议和治疗方案,仍需由专业医生进行审核确认,确保符合临床规范和实际诊疗需求。
Baichuan-M4相关资源
- arXiv技术论文:https://arxiv.org/pdf/2606.08982
Baichuan-M4的局限性
- 罕见疾病能力有限:官方技术报告指出,模型对于低频疾病和复杂罕见病场景的数据覆盖仍然有限,因此相关分析能力可能弱于常见疾病领域。
- 长期记忆依赖数据质量:如果患者历史资料存在缺失、错误或不完整情况,模型建立的长期记忆可能出现偏差,从而影响后续分析准确性。
- 影像能力受输入影响:胸部X光和皮肤病图像分析结果依赖图像质量。低分辨率、模糊或不规范拍摄可能导致模型判断准确率下降。
Baichuan-M4的典型应用场景
- 智能问诊场景:输入患者症状和病史信息,模型自动进行追问和风险筛查,输出结构化问诊记录,帮助提高接诊效率。
- 慢病管理场景:输入长期血压、血糖和健康记录数据,系统分析趋势变化并生成随访建议,辅助持续健康管理。
- 医学研究场景:输入具体医学问题后,系统自动检索临床研究和指南文献,输出带引用依据的医学分析结果。
- 病历处理场景:上传病历和检验报告后自动提取关键信息并生成结构化内容,降低人工录入和整理成本。
- 医学影像场景:上传胸部X光或皮肤病图像后,模型执行视觉分析并生成辅助诊断参考信息,提高初步筛查效率。
Baichuan-M4常见问题
Baichuan-M4怎么用?
Baichuan-M4可通过百川智能平台或合作医疗系统接入使用。用户上传病历、检验报告或医学影像后即可调用问诊、分析和检索能力。建议结合真实医疗场景测试,并由专业医生复核结果。
Baichuan-M4支持哪些医疗数据?
模型支持医疗文本、病历、检验报告、处方单、胸部X光和皮肤病图像等多种医疗数据类型,可实现多模态联合分析和推理。
Baichuan-M4和GPT-5.5哪个好?
在医疗专业任务中,Baichuan-M4的HealthBench成绩更高,幻觉率更低,更适合医疗问诊和临床辅助场景。GPT-5.5则在通用知识和跨领域任务中具备更广泛适用性。
Baichuan-M4适合医院部署吗?
模型具备长期患者管理、循证检索和医疗文档分析能力,适合医院辅助决策和健康管理场景。但最终诊疗决策仍需专业医生确认。
Baichuan-M4免费吗?
截至2026年6月公开资料显示,官方尚未公布统一商业定价和免费额度政策,具体接入方式和费用需以百川智能后续官方公告为准。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。
相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号