Unlimited-OCR快速摘要
Unlimited-OCR是百度于2026年6月推出的开源OCR模型,采用3B参数MoE架构和R-SWA注意力机制,支持40页以上长文档OCR、PDF解析、表格识别和公式提取。在OmniDocBench v1.6测试中取得93.92分,推理速度达到5580 TPS,适用于企业档案数字化和学术文献处理场景。
- 模型名称:Unlimited-OCR
- 开发公司:百度
- 发布时间:2026年6月22日开源
- 模型架构:3B参数MoE架构,500M激活参数
- 核心功能:长文档OCR、多页PDF解析、表格识别、公式识别、阅读顺序恢复
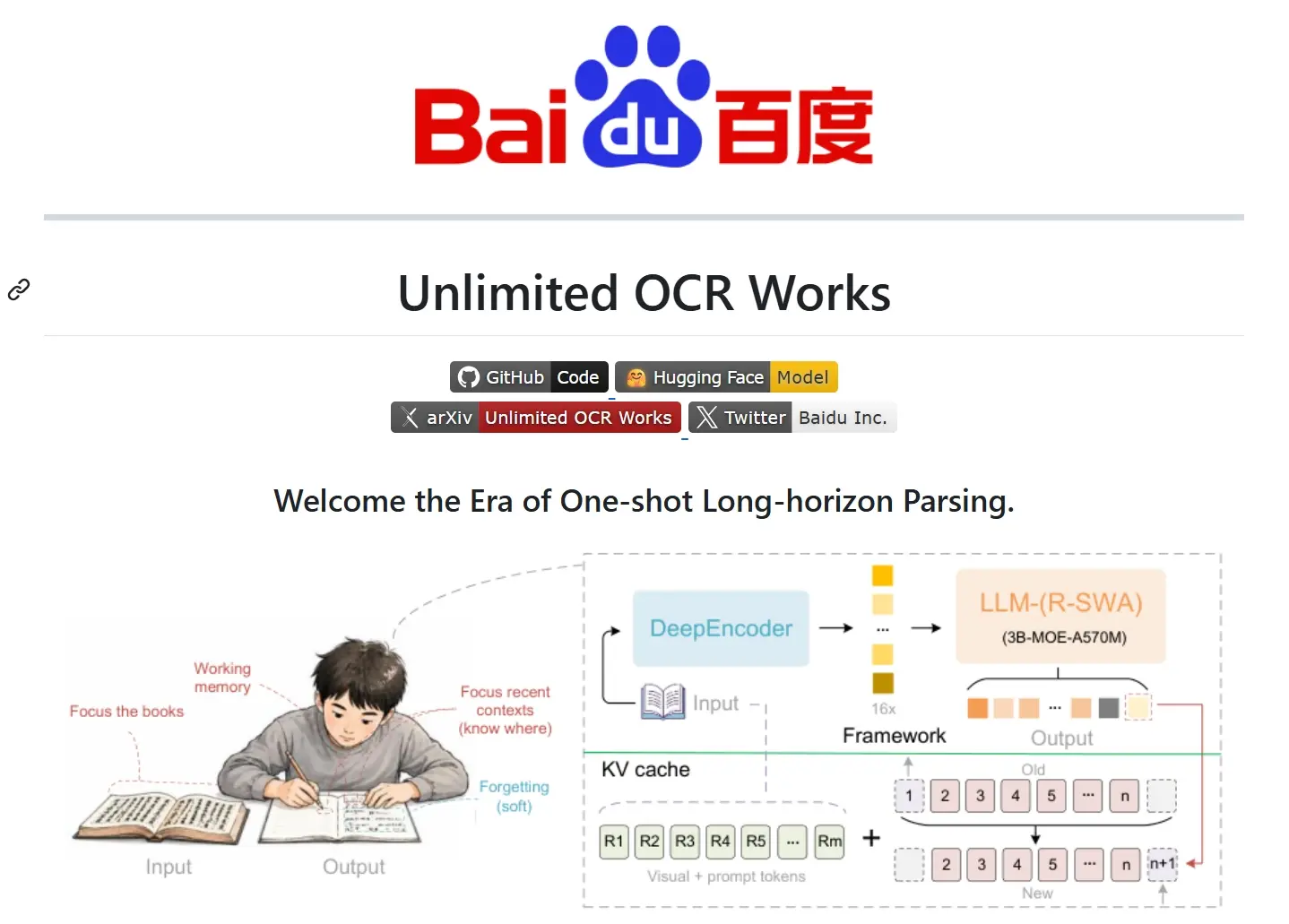
- 技术特点:R-SWA参考滑动窗口注意力机制、常数KV Cache设计
- 最大输出:支持32K长输出序列
- 长文档能力:支持40页以上文档单次前向解析
- 性能表现:OmniDocBench v1.6:93.92分;推理速度:5580 TPS
- 开源情况:模型权重与代码均已开源,采用MIT License
Unlimited-OCR的核心优势
- 超长文档解析:Unlimited-OCR支持40页以上PDF单次前向识别,无需传统OCR常见的分页循环处理方式,在档案、书籍和论文场景中可直接完成连续内容提取。
- 公开测试成绩突出:模型在OmniDocBench v1.5获得93.23分,在OmniDocBench v1.6达到93.92分,公开成绩高于DeepSeek-OCR系列模型,覆盖文本、表格和公式等核心任务。
- 资源占用稳定:R-SWA机制将KV Cache控制在固定规模,随着输出内容增长,显存占用和推理延迟不会同步增加,更适合长文档OCR任务。
- 推理效率较高:公开数据显示模型推理速度达到5580 TPS,在处理长篇报告、教材和研究资料时能够缩短整体处理时间,提高批量任务效率。
- 结构化输出完整:支持文本识别、公式恢复、表格解析和阅读顺序重建,可直接输出适用于知识库、RAG系统和内容管理平台的结构化结果。
Unlimited-OCR的核心功能
- 多页PDF识别:支持40页以上文档连续解析,上传整本论文、技术手册或扫描档案后,可一次生成完整文本内容,无需额外分页调度。
- 复杂版面解析:适用于教材、杂志、研究报告和试卷等复杂排版场景,能够识别多栏布局、图片混排和章节结构,恢复正确阅读顺序。
- 公式识别输出:支持数学公式提取与结构恢复,可处理积分、矩阵和统计公式等内容,适用于科研文献整理和教育资料数字化。
- 表格结构提取:支持财务报表、统计表和跨行跨列表格识别,输出结构化数据,方便后续导入数据库或进行数据分析。
- 长文本连续生成:最大支持32K输出长度,可一次完成大型文档转录任务,减少传统OCR模型因上下文限制带来的内容割裂问题。
Unlimited-OCR的技术原理
- R-SWA机制:Reference Sliding Window Attention仅保留参考Token和最近128个输出Token参与计算,降低长序列推理的计算与缓存压力。
- 常数KV Cache:通过固定容量缓存队列替代传统线性增长方案,使模型在长文档生成过程中保持稳定显存占用和推理效率。
- 视觉编码器:采用SAM-ViT与CLIP-ViT组合架构,将1024×1024图像压缩为256个视觉Token,在降低计算量的同时保留关键信息。
- MoE解码器:模型总参数规模为3B,激活参数约500M,通过专家路由机制动态分配计算资源,提高推理效率。
- 长输出训练:基于DeepSeek-OCR继续训练约4000步,并支持32K输出长度,使模型能够处理超长文档OCR任务。
Unlimited-OCR与主流模型对比
| 维度 | Unlimited-OCR | DeepSeek-OCR | GLM-OCR | Mistral OCR |
|---|---|---|---|---|
| 开发方 | 百度 | DeepSeek | 智谱AI | Mistral AI |
| 长文档支持 | 40+页 | 需分页 | 支持 | 支持 |
| 架构特点 | R-SWA | 全注意力 | VLM | OCR模型 |
| OmniDocBench v1.6 | 93.92 | 90.25 | 未公开 | 未公开 |
| 推理速度 | 5580 TPS | 4951 TPS | 未公开 | 未公开 |
| 开源情况 | 开源 | 开源 | 部分开放 | 闭源 |
Unlimited-OCR与DeepSeek-OCR最大的区别在于长文档推理架构。DeepSeek-OCR采用传统全注意力机制,输出越长缓存开销越大;Unlimited-OCR通过R-SWA实现常数级KV Cache管理,因此在数十页文档场景中更具优势。GLM-OCR更侧重文档理解与多模态问答,而Mistral OCR主要提供云端OCR能力。从公开测试数据看,Unlimited-OCR在长文档处理效率和OmniDocBench成绩方面表现较为突出。
如何使用Unlimited-OCR
- 下载模型:通过GitHub
baidu/Unlimited-OCR或Hugging Facebaidu/Unlimited-OCR获取源码和权重文件,准备支持CUDA的GPU环境。 - 部署环境:安装Transformers或SGLang推理框架,并配置模型运行依赖。
- 上传文档:输入PDF或页面图像文件,多页文档可直接提交,无需手动分页处理。
- 获取结果:模型自动输出文本、公式、表格和版面结构,可保存为Markdown或结构化数据格式。
Unlimited-OCR的局限性
- 商业服务信息有限:当前公开资料主要围绕开源模型和研究成果,尚未公布统一商业API及定价方案。
- 部署依赖GPU资源:虽然采用MoE架构降低激活参数规模,但长文档批量处理仍需要较高算力支持。
- 生态仍在发展:作为2026年发布的新模型,目前第三方工具链、案例和企业级集成资源相对有限。
Unlimited-OCR相关资源
- GitHub仓库:https://github.com/baidu/Unlimited-OCR
- HuggingFace模型库:https://github.com/baidu/Unlimited-OCR
- 技术论文:https://arxiv.org/abs/2606.23050
Unlimited-OCR的典型应用场景
- 企业档案数字化:批量处理扫描合同、历史档案和内部资料,输出可检索文本和结构化数据。
- 学术论文解析:识别论文中的正文、公式和表格内容,便于知识库建设和文献检索。
- 教育资料整理:处理教材、试卷和练习册,恢复版面结构并提取题目内容。
- 法律文档分析:将长篇合同和法规文件转换为可搜索文本,为后续审查和分析提供基础数据。
- 图书数字化:支持书籍、杂志和期刊内容转录,适用于数字图书馆和知识管理场景。
Unlimited-OCR常见问题
Unlimited-OCR怎么用?
下载模型权重后,通过Transformers或SGLang完成部署,上传PDF或图像即可执行OCR任务,适合本地化和私有化场景。
Unlimited-OCR免费吗?
Unlimited-OCR已开源发布,代码和模型权重可获取,但实际使用仍需承担服务器和GPU资源成本。
Unlimited-OCR和DeepSeek-OCR哪个好?
从公开测试结果看,Unlimited-OCR在OmniDocBench v1.6取得93.92分,同时更适合超长文档连续解析场景。
Unlimited-OCR支持多页PDF吗?
支持。模型可完成40页以上文档单次前向解析,无需传统分页处理流程。
Unlimited-OCR是否提供商业API?
截至目前公开资料,官方尚未公布统一商业API服务,企业用户主要通过开源方式部署使用。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。
相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号