Qwen-Image-Bench快速摘要
Qwen-Image-Bench是阿里巴巴通义千问团队推出的文生图模型评测体系,支持创作能力、多模态理解与真实世界还原分析,适用于AI图像模型评测、生成质量对比与AIGC研究场景。
- 模型名称:Qwen-Image-Bench
- 开发公司:阿里巴巴通义千问团队
- 发布时间:2026年5月
- 核心定位:面向创作者场景的Text-to-Image评测体系,强调“从生成到创作”的能力分析。
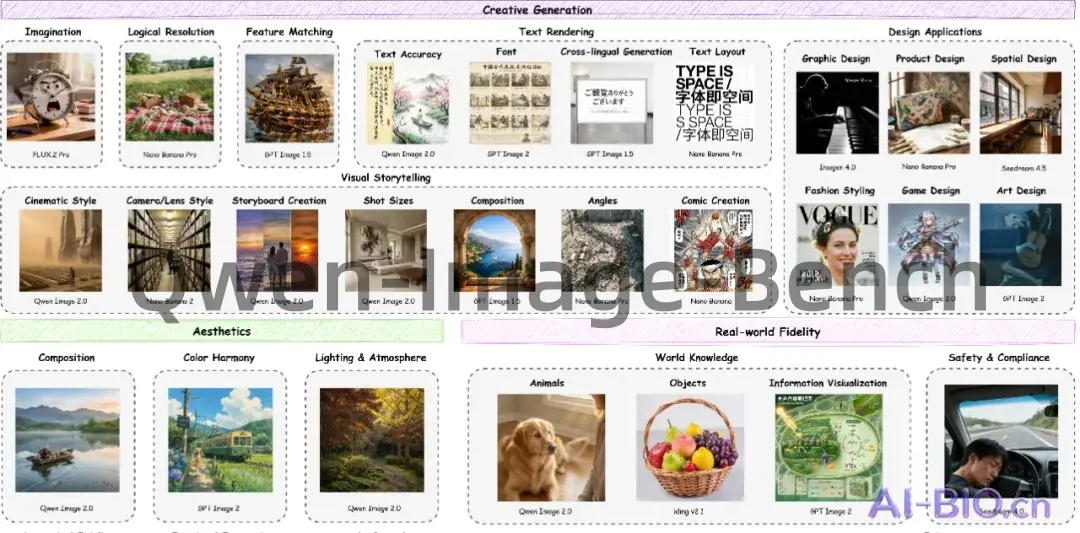
- 评测结构:采用5个L1维度、23个L2能力与56个L3细粒度指标构建三级层级评测框架。
- 评测维度:覆盖Quality、Aesthetics、Alignment、Real-world Fidelity与Creative Generation。
- 数据规模:包含1000条中英双语Prompt,其中500条长Prompt与500条短Prompt。
- 训练数据:Q-Judger基于13万+专家标注样本训练,采用80位艺术院校专业标注员三轮盲评。
- 一致性表现:Q-Judger与人工专家评分一致性达到Spearman ρ=0.92。
- 开源协议:采用Apache-2.0协议开放,支持本地部署与商业研究。
Qwen-Image-Bench的核心优势
- 创作者导向评测:Qwen-Image-Bench不再局限于传统文本对齐测试,而是增加真实世界还原与Creative Generation两大应用维度,可分析游戏设计、视觉叙事与信息可视化能力,适合商业AIGC平台与专业创作场景。
- 三级层级结构:系统采用5个L1维度、23个L2能力与56个L3指标构建层级化评测体系,可同时分析构图、文字渲染、世界知识与物理逻辑,相比单分值Benchmark具备更高区分能力。
- 高一致性评分:Q-Judger基于Qwen3.6-27B训练,并引入13万+双语专家标注样本,Spearman相关系数达到0.92,说明其评分结果与专业人工审美判断高度接近。
- 支持复杂创意任务:系统支持Comic Creation、Storyboard Creation、Game Design与Cross-lingual Generation等复杂创作能力评测,可检测AI模型在长Prompt与复杂视觉任务中的真实表现。
- 模型差异识别能力强:18个模型在Creative Generation维度出现30.6分差距,而Quality维度方差明显较低,说明基础图像质量已逐渐趋同,创意生成能力成为新核心竞争点。
Qwen-Image-Bench的核心功能
- 多维度图像质量分析:系统支持Realism、Resolution与Detail等维度检测,例如输入复杂城市海报后,可分析边缘清晰度、纹理噪点与光影自然度,用于AI绘图平台自动筛图与质量监控。
- 文本对齐能力测试:Qwen-Image-Bench支持复杂Prompt解析,例如输入包含角色动作、场景布局与文字排版的长文本后,可检测属性绑定、空间关系与场景一致性表现。
- 真实世界还原检测:系统可评测动物结构、人物动作与物理逻辑,例如识别人物接触关系、肢体穿模与世界知识错误,目前Physical Logic与Animals仍属于行业能力瓶颈。
- 创意生成能力评估:支持分镜、漫画、游戏设计与电影镜头风格分析,例如输入“赛博朋克漫画分镜”后,可检测镜头语言、叙事连续性与视觉表达能力。
- 自动化JSON评分:Q-Judger支持输出结构化JSON结果,可直接用于模型训练反馈、自动排序与企业AIGC工作流,适合批量图像生成平台构建自动评测流程。
Qwen-Image-Bench的技术原理
- 三级层级评测架构:Qwen-Image-Bench采用L1-L2-L3三级结构设计,其中L1包含5个核心能力维度,L2拆分23项子能力,L3进一步扩展为56个细粒度评测指标。
- Q-Judger评测模型:Q-Judger基于Qwen3.6-27B视觉语言模型训练,可同时接收Prompt与生成图像,再输出多维度结构化评分结果,支持JSON格式自动化推理。
- 专家监督训练:训练阶段引入13万+双语标注样本,由80位摄影、美术与导演方向专业标注员进行三轮独立盲评,提高Benchmark与人工审美的一致性。
- 复杂推理机制:系统并非只检测文本相似度,而是联合分析人物动作、镜头构图、世界知识与视觉叙事逻辑,可同时评估创意表达与真实感表现。
- 统一推理参数:评测阶段统一采用temperature=0、top_k=1与max_new_tokens=4096等固定参数,确保18个模型在相同推理环境下进行公平对比。
Qwen-Image-Bench与主流模型对比
| 对比维度 | Qwen-Image-Bench | GenEval | DPG-Bench | OneIG-Bench |
|---|---|---|---|---|
| 核心定位 | 创作者场景评测 | 文本对齐测试 | 复杂Prompt测试 | 图像质量评测 |
| 评测层级 | 5维度+56指标 | 单层结构 | 有限维度 | 单层结构 |
| 支持视觉叙事 | 支持 | 不支持 | 有限支持 | 不支持 |
| 支持跨语言文字生成 | 支持 | 弱支持 | 部分支持 | 有限支持 |
| 世界知识评测 | 支持 | 不支持 | 弱支持 | 不支持 |
| 适用场景 | 商业AIGC与研究 | 基础Benchmark | Prompt研究 | 图像生成分析 |
Qwen-Image-Bench与传统Benchmark最大的区别,在于其强调“创作能力”而不仅是“生成能力”。GenEval更偏向属性绑定与对象计数,而DPG-Bench主要关注长Prompt理解能力。Qwen-Image-Bench新增Creative Generation与Real-world Fidelity后,可分析游戏设计、跨语言文字生成、视觉叙事与世界知识理解。18个模型在Creative Generation维度出现30.6分差距,说明高阶创作能力已成为文生图模型真正的能力分水岭。GPT Image 2以64.69综合分位列第一,并在5个L1维度全部领先,而Qwen Image 2.0 Pro则位于第三梯队,在Alignment维度表现接近第一梯队。
如何使用Qwen-Image-Bench
- 下载评测环境:用户需先克隆Qwen-Image-Bench仓库,并安装PyTorch、Transformers与ms-swift环境,推荐
Python 3.11与24GB以上显存环境以保证推理稳定性。 - 准备测试数据:创建包含ID、prompt与image_path字段的JSONL文件,ID需对应metadata中的1-1000编号,建议统一生成分辨率为1024×1024以减少评测误差。
- 运行Q-Judger:通过judge.py调用
Qwen/Qwen-Image-Bench模型,系统会自动分析Quality、Alignment与Creative Generation等维度,并输出JSON结构化结果。 - 查看评分结果:评测完成后会生成bench_scores.xlsx文件,包含L1汇总与L2细节结果,开发者可根据低分项优化Prompt结构与模型训练方向。
- 构建自动化流程:企业平台可将Q-Judger接入AIGC工作流,实现“生成-评分-筛选”自动闭环,适用于AI海报、电商图与内容审核场景。
Qwen-Image-Bench相关资源
- Github仓库:https://github.com/QwenLM/Qwen-Image-Bench
- HuggingFace模型库:https://huggingface.co/datasets/Qwen/Qwen-Image-Bench
- arXiv技术论文:https://arxiv.org/pdf/2605.28091
Qwen-Image-Bench的局限性
- 实时评测延迟较高:Q-Judger基于Qwen3.6-27B训练,复杂任务推理耗时较长,更适合离线Benchmark场景,目前尚不适用于低延迟实时生成平台。
- 复杂动作识别仍有限:Physical Logic、Anatomical Fidelity与Contact Interaction等L3指标仍属于行业能力天花板,即便GPT Image 2相关评分也低于44。
- 主观审美仍存在差异:虽然Spearman一致性达到0.92,但艺术设计与品牌视觉仍具有主观性,因此商业级生成结果仍需要人工复核与风格调整。
Qwen-Image-Bench的典型应用场景
- AI模型发布评测:模型上线前可通过1000条中英双语Prompt分析生成稳定性、文字渲染与视觉叙事能力,验证是否达到商业发布标准。
- 多模型横向对比:开发者可同时测试Qwen Image、FLUX、GPT Image与Seedream系列模型,并根据L1与L2维度结果分析各模型优势与短板。
- 中文文字渲染测试:系统支持中文海报、PPT与电商Banner评测,可分析文字准确率、字体布局与文化元素生成效果。
- 创意设计能力分析:通过Game Design、Comic Creation与Storyboard等维度检测模型在高阶创意任务中的生成能力。
- 学术Benchmark研究:研究人员可引用Qwen-Image-Bench作为标准化评测数据集,提高论文实验结果的可复现性与可信度。
Qwen-Image-Bench常见问题
Qwen-Image-Bench怎么用?
Qwen-Image-Bench主要通过judge.py调用Q-Judger模型完成评测。用户需准备包含Prompt与图像路径的JSONL文件,再运行评测脚本生成多维度评分结果。
Qwen-Image-Bench支持免费使用吗?
Qwen-Image-Bench采用Apache-2.0协议开源,个人研究与商业测试均可使用。
Qwen-Image-Bench和GenEval哪个好?
两者定位不同。GenEval更适合基础文本对齐与属性绑定测试,而Qwen-Image-Bench增加Creative Generation与Real-world Fidelity后,更适合分析商业AIGC模型的创作能力与真实世界理解能力。
Qwen-Image-Bench支持哪些模型评测?
当前Benchmark已覆盖GPT Image 2、Nano Banana、Qwen Image 2.0 Pro、FLUX 2、Imagen 4与GLM Image等18个主流文生图模型,适用于统一Benchmark测试与能力分析。
Qwen-Image-Bench最大的特点是什么?
与传统Benchmark相比,Qwen-Image-Bench最大的特点是强调“从生成到创作”。Creative Generation维度支持视觉叙事、跨语言文字生成与游戏设计分析,可更真实反映文生图模型的商业创作能力。
 浙公网安备33010202004812号
浙公网安备33010202004812号