PawBench快速摘要
PawBench是由通义实验室与OpenJudge生态共同推进的通用智能体评测基准,面向Agent任务场景,评估模型与Harness联合表现,适用于个人助理与复杂工作流智能体评估。
- 项目名称:PawBench(LLM × Harness评测基准)
- 开发公司:阿里通义实验室 / AgentScope AI / OpenJudge生态
- 发布时间:2026年6月5日推出v1.0版本
- 主要功能:评估模型与智能体运行框架联合能力(Model × Harness交叉评测)
- 使用要求:Docker运行环境 + API模型接入 + Harness适配
- 开源情况:GitHub开源(agentscope-ai/PawBench)
- 适用场景:Agent评测、Harness优化、模型选型、智能体诊断
- 技术特点:150任务×4050测试单元×9模型×3 Harness交叉矩阵
- 价格:开源免费,成本主要来自API与计算资源消耗
PawBench的核心优势
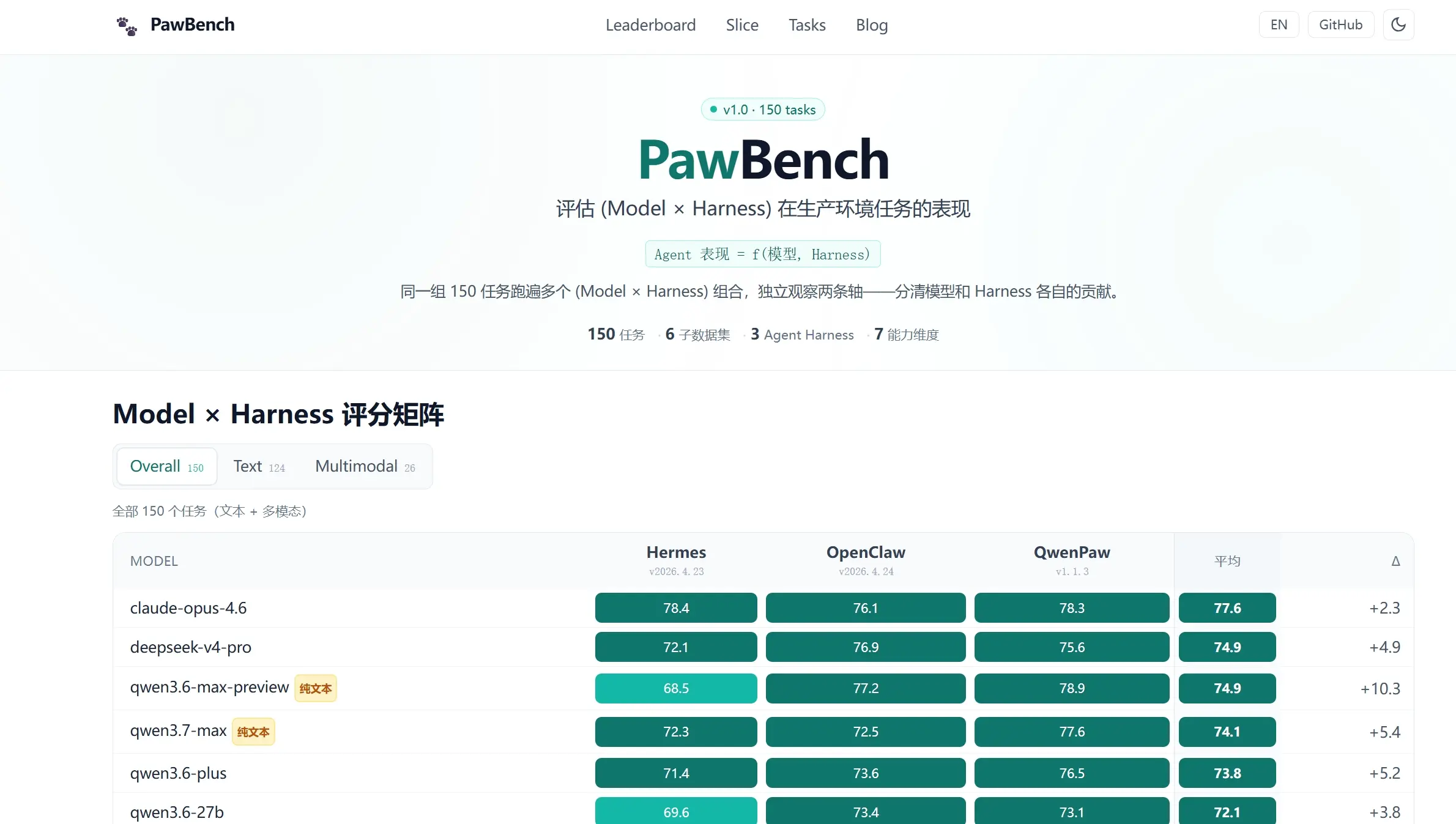
- Model×Harness联合评估优势:PawBench通过将模型与Harness纳入统一评测体系,实现联合能力测量。据官方评测矩阵(9模型×3Harness×150任务)显示,该方法可量化框架对模型能力释放的影响,例如同模型在不同Harness下最高差距达11.5分,来源OpenJudge v1.0数据。
- 真实任务覆盖优势:评测集包含150个真实Agent任务、4050个测试单元,覆盖办公协同、软件工程与Web搜索场景,任务来源于6个Agent评测集聚合,相比传统静态benchmark更贴近生产环境复杂链路。
- 切片诊断能力优势:支持Text、Multimodal及多维能力切片分析,通过scenario、capability、complexity等五维标签体系进行拆解,可定位Skill调用失败或工具路径错误等问题来源。
- Harness差异量化优势:根据官方榜单数据,QwenPaw与Hermes在平均表现上差距约6.4分,说明Harness设计本身对模型输出具有显著影响,可用于框架优化与工程调优。
- 可复现轨迹优势:所有任务运行于Docker沙箱环境,完整记录workspace、执行轨迹与grader结果,支持失败任务逐步回溯分析,有助于定位工具调用或环境配置问题。
PawBench的核心功能
- 交叉评测功能:构建Model×Harness×Task三维矩阵,通过150任务在9模型与3Harness间运行,实现4050测试单元统一评分,可输出Overall与切片分数用于横向比较。
- 混合评分机制:结合规则断言与LLM-as-judge评分体系,例如文件是否生成、代码是否通过测试与语义质量共同决定最终0-1分数,提高评估稳定性与语义覆盖能力。
- 任务五维标注功能:每个任务标注scenario、capability、complexity、modality、environment五个维度,例如L1-L3复杂度与text/multimodal区分,支持精细化分析。
- Skill与工具评测功能:重点评估Skill Use、Tool Use及Planning能力,例如技能加载失败或路径感知错误可被单独切片识别,用于优化Agent运行逻辑。
- Web与多环境任务功能:支持开放环境与闭环环境评测,包括Web搜索、API调用与文件操作任务,可模拟真实智能体执行链路。
PawBench的技术原理
- 交叉评测矩阵架构:采用9模型×3Harness×150任务构成控制变量实验结构,通过固定任务与变量切换隔离模型能力与框架能力影响,实现能力分解分析。
- Docker沙箱隔离机制:每个任务在独立容器执行,记录workspace状态、文件产物与系统日志,确保运行环境一致性与结果可复现性。
- 混合评分系统:自动评分器负责结构化判断(如exit code与文件存在性),LLM judge负责语义质量评分,两者加权生成最终0-1分。
- 产物级硬校验机制:通过检查文件落盘、diff变化与测试结果避免“虚假完成”,例如仅声明完成但未生成文件会被判定失败。
- Harness控制变量机制:通过不同Harness(Hermes/OpenClaw/QwenPaw)对同一模型进行包装测试,分析工具数量、workspace感知与Prompt结构对性能影响。
PawBench与主流模型对比
| 对比维度 | PawBench | SWE-bench | AgentBench |
|---|---|---|---|
| 核心定位 | 评估Model×Harness联合效果,拆分模型能力与运行框架贡献,用于Agent系统级诊断与优化 | 评估模型在真实GitHub代码修复任务中的能力,强调软件工程问题解决 | 评估通用Agent在多环境(OS/DB/Web)中的交互与决策能力 |
| Harness/框架评估 | ✅核心评估对象之一,明确量化Harness影响(如工具、Skill、Workspace) | ❌不评估框架,仅关注模型输出结果 | ❌不拆分框架变量,视为环境内置部分 |
| 任务来源 | 6个Agent数据集聚合(150任务/4050单元),覆盖办公、Web与工程任务 | 真实GitHub Issue与PR数据(2000+) | 合成多环境任务(约1000+) |
| 典型任务 | 办公自动化、软件工程、Web搜索、Skill调用、文件操作等真实Agent链路任务 | 代码Bug修复、功能实现、单元测试通过 | 操作系统交互、数据库查询、网页浏览与决策任务 |
| 评分机制 | 规则断言+LLM-as-judge混合评分,范围0-1,兼顾结构正确性与语义质量 | 单元测试通过率(二元成功/失败) | 基于环境执行成功率与任务完成度评分 |
| 环境隔离 | Docker沙箱+workspace产物+执行轨迹记录,支持回放与失败分析 | 代码仓库隔离环境+测试容器 | 多环境模拟系统(OS/DB/Web等) |
| 任务标签体系 | 五维标签:scenario、capability、complexity、modality、environment | 按仓库/语言划分,无统一能力标签体系 | 按环境类型分类(OS/DB/Web等) |
| 榜单维度 | Overall / Text / Multimodal + slice分析(能力/场景/模态) | Verified / Full等代码任务分榜 | 按环境类型分榜(OS/DB/Web等) |
| 失败诊断能力 | 保留trace、workspace、grader与产物,可逐层定位失败来源(工具/Skill/路径) | 仅保留测试日志与patch结果 | 保留环境交互日志,诊断能力有限 |
| 零配置评测 | 支持“clone即跑”,默认Docker+API配置即可运行 | 需配置代码仓库与运行环境 | 需配置多种环境模拟器 |
| 最佳适用 | Agent系统优化、Harness调优、模型+框架选型与诊断分析 | 代码模型能力评估与软件工程任务研究 | 通用Agent能力评估与多环境决策研究 |
从标准化benchmark维度来看,PawBench与SWE-bench、AgentBench的核心差异在于是否引入Harness作为独立评估变量。根据OpenJudge与通义实验室v1.0公开结果,PawBench通过9模型×3Harness×150任务的交叉矩阵,将模型能力与框架能力解耦分析,使同一模型在不同Harness下最高出现约11.5分差异。相比之下,SWE-bench与AgentBench均未显式建模框架变量,因此更偏向“模型能力单轴评估”。在工程价值上,PawBench更适用于Agent系统调优与失败归因分析,而不仅仅是模型排名。
如何使用PawBench
- 环境配置步骤:安装Python3.11+与Docker环境,配置API密钥(如DashScope或OpenAI兼容接口),初始化评测依赖库并加载任务数据集。
- 模型接入步骤:在配置文件中填入模型API与参数,如
temperature=0.2、max_tokens=4096,用于保证不同模型评测一致性与可比性。 - 选择任务切片:可选择Overall(150任务)、Text(124任务)或Multimodal(26任务),用于不同场景能力评估与对比分析。
- 运行评测流程:通过
run_bench.py启动任务,每个任务在独立Docker容器执行,并记录workspace产物、工具调用日志与执行轨迹。 - 结果分析与提交:系统生成Overall与slice分数,可上传至Leaderboard进行排名,同时支持trace回放分析失败原因。
PawBench的局限性
- Harness依赖敏感性:评测结果对Harness配置高度敏感,在不同工具数量与Prompt结构下分数波动可达10分以上,来源OpenJudge v1.0数据说明该问题仍未完全标准化。
- 多模态样本占比有限:Multimodal任务仅26/150,占比约17%,导致多模态能力评估稳定性低于文本任务,复杂视觉推理覆盖仍需扩展。
- LLM judge不确定性:语义评分依赖模型判断,可能引入偏差,目前采用混合评分降低风险,但仍存在评估一致性问题,官方计划持续优化judge rubric。
PawBench相关资源
PawBench的典型应用场景
- 模型选型场景:输入多模型API与统一任务集,通过Harness固定输出,比较整体分数与切片表现,输出最优模型组合用于生产环境。
- Harness优化场景:输入同一模型与不同Harness配置,运行150任务并对比差异,输出Skill加载或工具调用失败的优化方向。
- Agent系统调试场景:输入失败任务trace日志,分析workspace与工具调用链,定位路径错误或产物缺失问题。
- 多模态能力评估场景:输入图像或视频任务,测试模型在视觉理解与跨模态推理中的表现差异。
- Web搜索能力评估场景:输入网络检索任务,测试Agent在开放环境中的信息抓取与整合能力输出质量。
PawBench常见问题
PawBench如何计费与使用成本如何构成?
PawBench本身为开源项目,不收取使用费用,但运行评测需调用模型API与Docker计算资源,成本取决于模型调用量与任务规模,建议批量运行以降低单任务成本并优化资源利用效率。
PawBench和SWE-bench哪个好?
SWE-bench更侧重代码修复能力评估,PawBench强调模型与Harness联合效果,根据OpenJudge设计理念,PawBench更适合Agent系统优化与框架调优,而SWE-bench适合纯模型编码能力评估。
PawBench怎么使用?
通过GitHub克隆项目后配置Docker与API密钥,选择任务切片运行run_bench.py执行评测,系统自动生成分数与trace日志,适合模型对比与Harness调试使用。
PawBench支持实时任务吗?
PawBench支持Web与开放环境任务,但并非实时流式系统,任务以Docker批处理执行为主,适合离线评测与复现实验,不适合实时交互场景。
PawBench有免费额度吗?
PawBench开源免费使用,无官方计费机制,但API调用与计算资源由用户自行承担,建议使用低成本模型进行初步验证,再切换高性能模型进行最终评估。

 浙公网安备33010202004812号
浙公网安备33010202004812号