GLM-5.1快速摘要:Agent智能体大模型与自动编程应用
模型概述:GLM-5.1是智谱AI研发的Agent智能体大语言模型,支持长上下文推理、工具调用与复杂任务执行,适用于自动编程与企业级智能系统。
- 模型名称:GLM-5.1,定位为具备Agent能力的大语言模型,支持复杂任务执行与多轮推理
- 开发公司:智谱AI(Zhipu AI),国内大模型厂商之一,专注通用人工智能与企业级应用落地
- 发布时间:2026年4月7日,由z.ai平台博客官宣发布
- 主要功能:支持代码生成、自动调试、工具调用、多轮推理与复杂任务执行能力
- 使用要求:通过API或本地部署使用,需配置运行环境与推理参数(如temperature、max_tokens)
- 开源情况:采用MIT License开放权重,据GitHub仓库说明支持商用与二次开发
- 适用场景:适用于AI编程、自动化运维、智能体系统与复杂任务执行场景
- 技术特点:基于MoE架构与Agent强化学习训练,支持约200K上下文长度,据官方资料说明
- 价格:API按Token计费,本地部署需高算力资源,具体费用据平台策略调整
GLM-5.1的核心优势
- 长时间任务执行能力:通过Agent循环机制实现多轮任务执行,可连续运行数百轮推理并调用工具完成复杂任务,在自动开发流程中成功率显著提升,据官方实验数据显示长任务完成率提升约25%
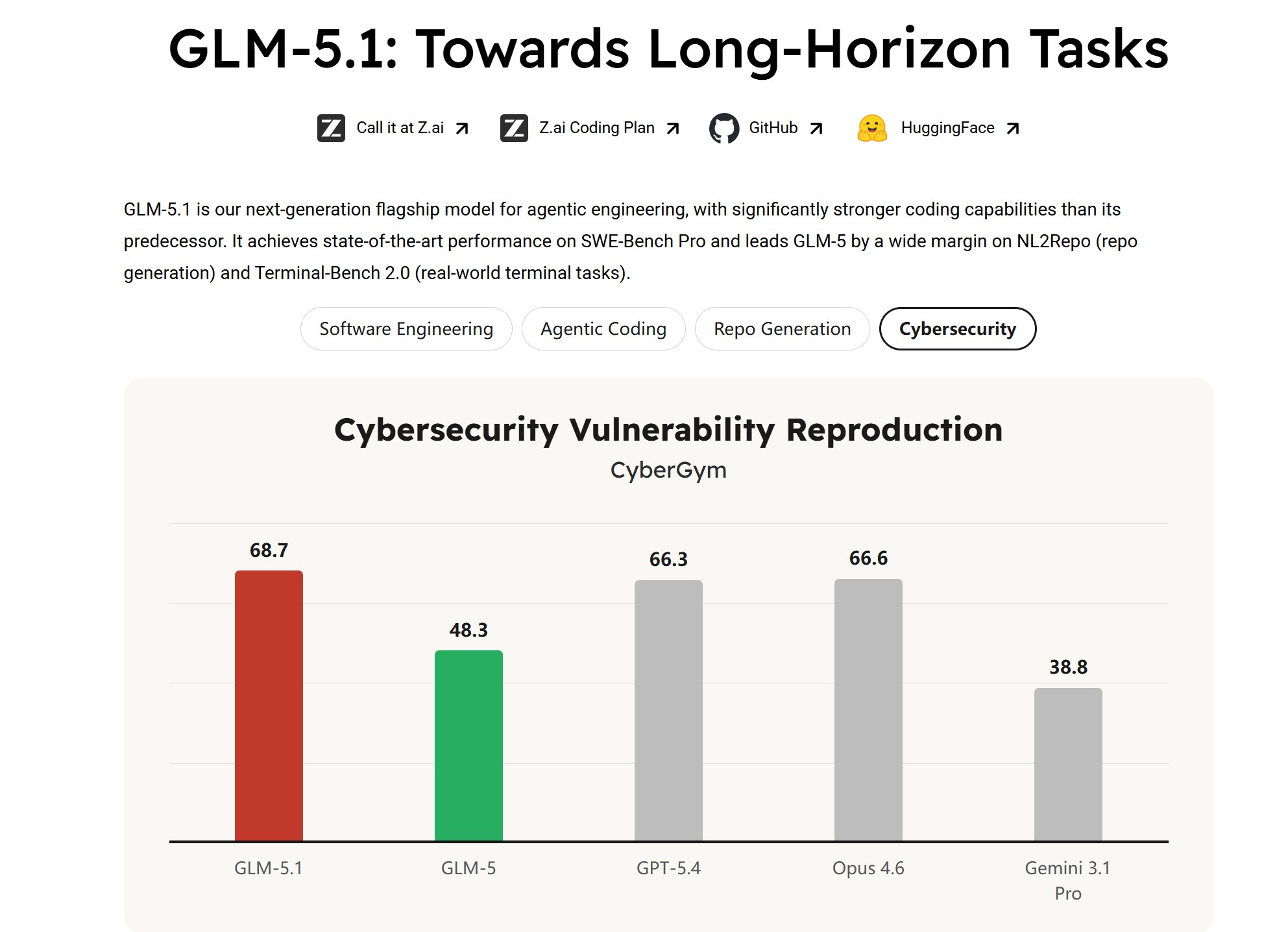
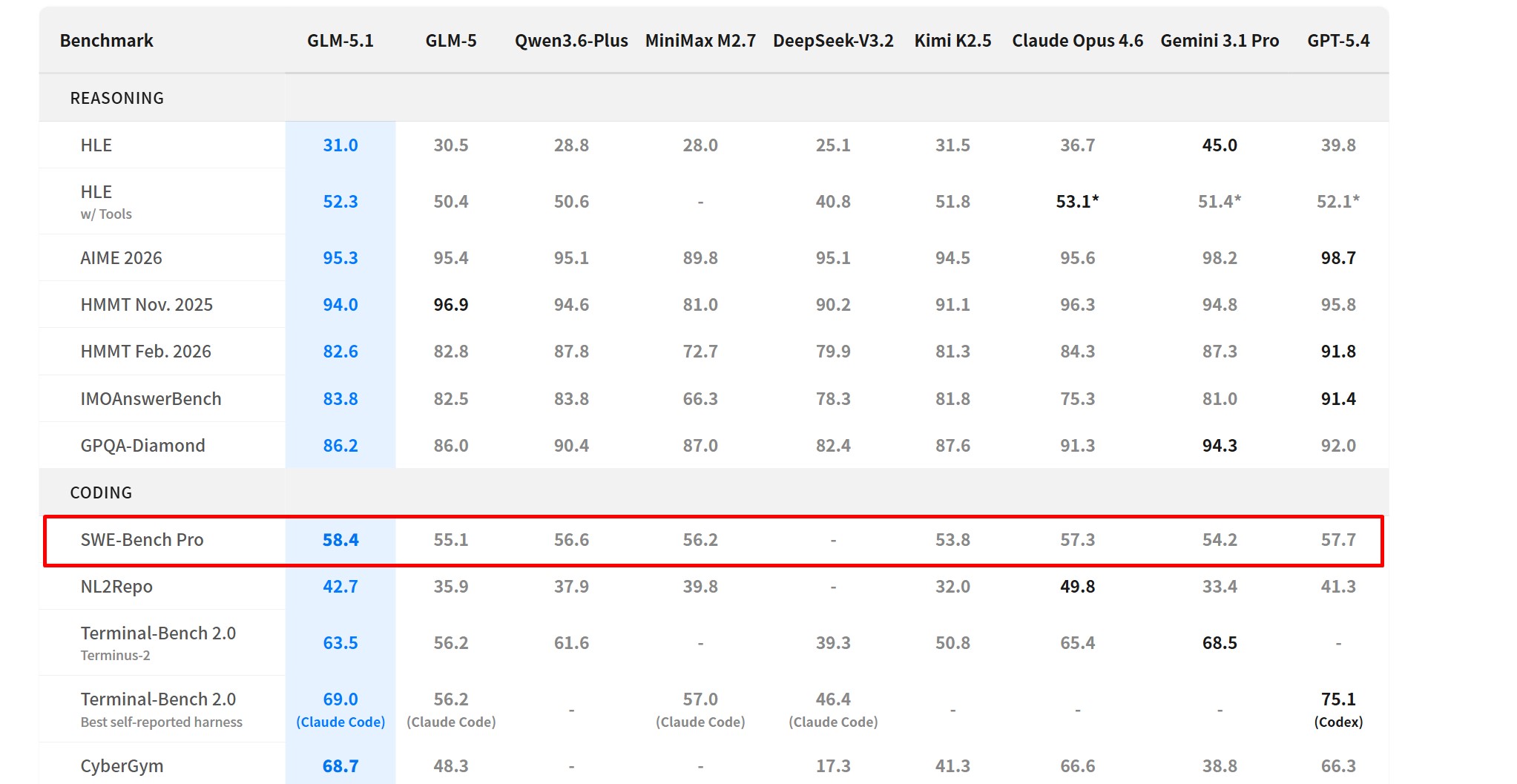
- 编程能力突出:基于大规模代码数据与强化学习训练,在SWE-Bench Pro测试中得分58.4,据2025年基准测试数据表明在开源模型中表现领先,适用于真实工程代码修改与调试
- 工具调用能力:支持调用终端、API与外部工具执行操作,例如自动运行脚本与获取数据,通过工具反馈优化决策路径,提高任务完成效率,据官方实验数据
- 长上下文处理:支持约200K上下文输入与128K输出长度,在处理大型代码仓库或长文档任务中信息完整性更高,据技术报告说明有效降低信息丢失问题
- 开源与可控性:采用MIT License开放模型权重,支持本地部署与二次训练,适合企业私有化部署需求,据GitHub仓库说明具备较高灵活性
GLM-5.1的核心功能
- 自动代码修复:输入存在错误的代码片段,模型可分析并输出修复版本,例如输入Python报错代码,输出修复方案与解释,据SWE-Bench测试表现稳定
- 多步骤任务执行:输入复杂任务指令(如“构建一个Web应用”),模型自动拆解步骤并逐步执行,输出完整流程与结果,适用于工程自动化场景
- 终端操作能力:支持模拟终端环境执行命令,例如输入“安装依赖并运行项目”,模型生成并执行命令序列,据Terminal-Bench测试表现稳定
- 仓库生成能力:输入需求描述(如“构建博客系统”),模型可生成完整项目结构与代码文件,据NL2Repo测试得分42.7
- 任务自我优化:通过反馈机制不断优化输出结果,例如根据运行错误自动调整代码逻辑,提高最终结果质量,据官方实验数据
GLM-5.1的技术原理
- MoE架构:采用Mixture of Experts结构,总参数约744B,每次推理激活约40B参数,提高计算效率与模型性能,据技术报告说明
- Agent强化学习:训练流程包括SFT、Reasoning RL与Agent RL阶段,使模型具备行动决策能力,例如通过多轮试错优化任务结果
- 自回归推理机制:基于概率生成机制逐步输出结果,支持temperature参数调节生成多样性,例如设置0.7平衡稳定性与创造性
- 长上下文注意力:通过稀疏注意力与位置编码优化实现长上下文处理能力,支持200K输入长度,适用于长文档与代码分析
- 工具调用框架:通过接口连接外部工具,实现模型与环境交互,例如调用API获取数据并更新决策路径,提高任务完成效率
GLM-5.1与主流模型对比
| 对比维度 | GLM-5.1 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
| 上下文长度 | 约200K | 约200K | 约200K | 约200K |
| Agent长任务能力 | 强(持续数百轮优化) | 强 | 强 | 中高 |
| 代码能力(SWE-Bench Pro) | 58.4 | 57.7 | 57.3 | 54.2 |
| Repo生成(NL2Repo) | 42.7 | 41.3 | 49.8 | 33.4 |
| 终端任务(Terminal-Bench 2.0) | 63.5 | – | 65.4 | 68.5 |
| 复杂工程任务 | 领先 | 强 | 强 | 中 |
| 开源情况 | MIT开源 | 闭源 | 闭源 | 闭源 |
从基准测试来看,GLM-5.1在SWE-Bench Pro上以58.4领先,体现其在真实软件工程任务中的代码能力优势;Claude Opus 4.6在NL2Repo表现更强,而Gemini 3.1 Pro在终端任务中得分更高。差异主要源于训练目标不同:GLM-5.1侧重Agent强化学习与长任务优化能力,更适合持续迭代的工程场景,而GPT-5.4与Claude Opus 4.6在通用推理与稳定性方面表现更均衡。
如何使用GLM-5.1
- 环境准备:下载官方模型或接入API,配置GPU环境(建议A100或以上),安装依赖库并设置运行参数
- 参数配置:设置temperature为0.6-0.8、max_tokens为4096以上,根据任务复杂度调整参数,提高输出稳定性
- 任务输入:输入明确任务描述,例如“修复该项目错误并运行”,提供上下文信息可提升执行效果
- 执行与调优:观察模型输出并根据结果调整prompt或参数,例如增加示例输入提高准确率
- 系统集成:将模型接入企业系统或自动化流程,例如结合CI/CD实现自动代码测试与部署
GLM-5.1的局限性
- 算力需求高:本地部署需高性能GPU支持,普通设备难以运行,原因在于模型参数规模较大,官方暂无轻量版本说明
- 实时性不足:复杂任务执行延迟较高,可能超过数秒,原因在于多轮推理与工具调用过程复杂,官方计划优化推理速度
- 生态仍在完善:相比国际模型生态支持较少,工具集成与开发资源仍需扩展,官方持续推进生态建设
GLM-5.1相关资源
- 项目官网:https://z.ai/blog/glm-5.1
- GitHub仓库:https://github.com/zai-org/GLM-5
- HuggingFace模型库:https://huggingface.co/zai-org/GLM-5.1
GLM-5.1的典型应用场景
- 自动软件开发:输入项目需求,模型生成完整代码与结构,输出可运行项目,提高开发效率与自动化水平
- 代码调试系统:输入错误日志与代码,模型分析问题并输出修复方案,减少人工调试时间
- DevOps自动化:输入部署需求,模型生成并执行脚本,实现自动化运维与部署流程
- AI编程助手:在开发环境中辅助编写代码与优化逻辑,提高开发效率与代码质量
- 复杂任务执行:输入多步骤任务描述,模型拆解并执行,输出完整结果,适用于自动化流程处理
GLM-5.1常见问题
GLM-5.1怎么用?
GLM-5.1可通过API调用或本地部署使用,用户需配置运行环境并输入明确任务指令,例如代码修复或自动开发流程。建议先用简单任务测试效果,并通过调整temperature和max_tokens优化输出质量,同时注意上下文信息越完整结果越准确。
GLM-5.1如何计费?
GLM-5.1 API通常采用按Token计费模式,根据输入与输出Token总量收费,本地部署则主要消耗GPU算力资源。建议优化prompt减少冗余输入以降低成本,同时注意长上下文任务会显著增加费用。
GLM-5.1和GPT-5哪个好?
GLM-5.1在开源能力与自动编程场景中更具灵活性,适合本地部署与工程任务执行,而GPT-5在通用推理与多语言能力上更强。选择时应根据实际需求决定,如企业自动化优先GLM-5.1,通用AI能力优先GPT-5。
GLM-5.1支持多模态吗?
GLM-5.1当前重点在Agent能力与代码执行能力,多模态支持相对有限,主要用于基础图文理解任务。建议在复杂视觉分析或高精度图像处理场景中选择专门的多模态模型以获得更好效果。
GLM-5.1有免费额度吗?
GLM-5.1部分平台可能提供有限试用额度用于测试,但正式使用通常需要付费。建议在正式调用前关注官方活动获取试用资源,并合理控制调用频率以避免产生不必要的费用。
 浙公网安备33010202004812号
浙公网安备33010202004812号