一、2026 企业 AI 变局:从“对话模型”转向“垂直知识引擎”
进入 2026 年,企业级 AI 的核心矛盾已经不再是“模型能不能用”,而是“模型是否真正融入业务逻辑”。随着 DeepSeek-R1 等推理型模型的成熟,AI 正从以往的通用对话工具,逐步演进为可承载企业制度、流程与决策逻辑的垂直知识引擎。
从 AI 工具导航站 ai-bio.cn 的长期跟踪来看,企业用户普遍遇到三个现实问题:第一,网页对话无法稳定处理几十到上百页的内部文档;第二,模型推理质量在复杂业务场景中频繁“跑偏”;第三,数据合规与权限控制难以通过简单提示词解决。尤其是在万知(Wanzhi)功能结构调整、公有云算力阶段性紧张的背景下,这些问题被进一步放大。
老高在 1 月 26 日针对 DeepSeek-R1 的多轮实测中发现:当企业直接将 R1 用于处理大规模文档集合(合同、制度、技术规范)时,如果缺乏底层 RAG(检索增强生成)架构支持,模型即便具备完整推理能力,也极易出现逻辑错配、条款混淆等问题。本文将结合 Dify 与 FastGPT 的真实配置路径,系统拆解如何在不增加硬件成本、不牺牲推理能力的前提下,构建一个可长期运行的企业级私有 AI 知识系统。
二、硬件与架构避坑:为什么多数企业不适合自建“真私有化”
在企业 AI 落地过程中,“私有化部署”几乎是绕不开的话题,但也是被误解最深的概念之一。大量企业将私有化简单等同于“自购服务器”,却忽视了推理型大模型对硬件与运维的真实要求。
以完整版 DeepSeek-R1(671B 参数规模)为例,其在完整推理场景下,对显存、带宽、并发调度都有极高要求。即便通过量化或裁剪,也难以在保证逻辑稳定性的同时兼顾成本与维护复杂度。
| 方案类型 | 初始成本 | 推理质量 | 维护复杂度 | 典型适用场景 |
|---|---|---|---|---|
| 本地私有化(4-bit 压缩) | 5–10 万级 | 逻辑尚可,但并发能力极低 | 高 | 极高敏感度数据的脱密处理 |
| 蒸馏版私有化(7B–32B) | 千元级 | 明显降智,难以支撑复杂推理 | 中 | 简单问答或流程自动化 |
| 云端满血 API(企业加密接入) | 按量计费 | 完整推理能力 | 低 | 多数企业知识库与办公场景 |
经验结论:除非涉及国防级或法律强制本地化的数据,大多数企业在 2026 年更合理的选择是“云端满血模型 + 企业级加密通道 + 私有知识库”,而不是盲目投入重资产服务器。
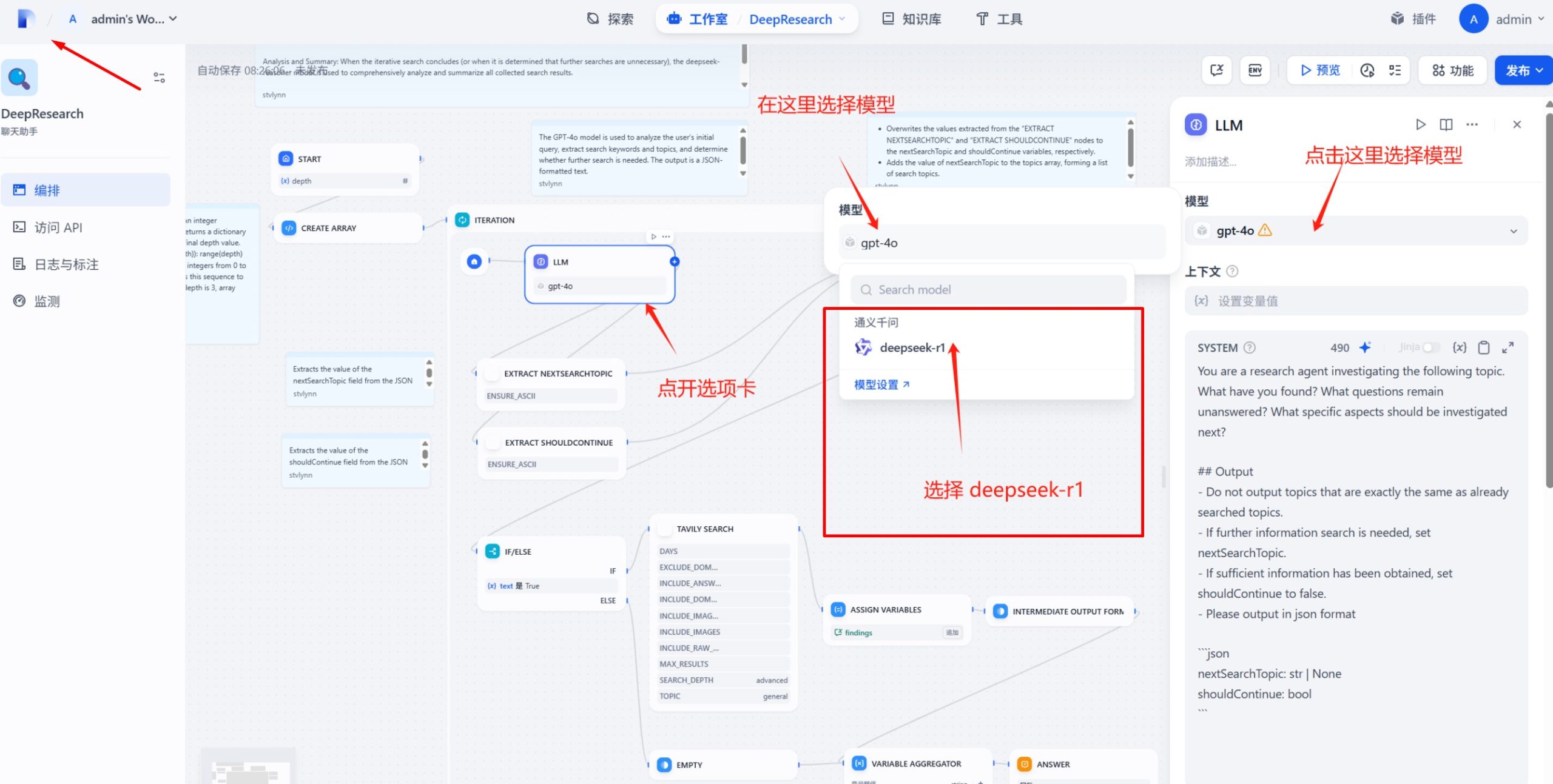
三、Dify 知识库实测:最容易被忽视的三个底层配置问题
在通过 API 挂载 DeepSeek-R1 后,不少企业会发现模型回答“看似正确,但无法落地”。问题往往不在模型本身,而在知识检索链路的配置细节。
1. 索引模式选择错误:语义能力被浪费
Dify 提供“经济模式”和“高质量模式”两种索引方式。前者以关键词匹配为主,几乎无法发挥 R1 的语义理解优势。在企业级知识库场景中,应优先选择高质量索引模式,并配置高性能向量模型(具体模型取决于所接入的服务商与部署环境)。
只有当文档被正确向量化,R1 的推理过程才建立在“理解内容”而非“拼接关键词”之上。
2. 分段策略失误:上下文被人为切断
固定长度切分是导致 RAG 幻觉的重要原因之一。合同条款、制度章节往往具有强上下文依赖,如果被粗暴拆分,模型在推理时将缺乏必要背景。
实践中,更有效的方式是采用父子分段(Parent-Child Chunking)策略:
- 子段:100–200 字符,用于精确检索命中。
- 父段:1000 字符以上,用于提供完整语义背景。
当子段被命中后,系统将对应父段整体提供给 R1,显著降低长文逻辑崩盘概率。
3. 检索策略单一:专有名词识别失败
仅依赖语义检索,在企业内部存在大量专有名词、编号、函数名的情况下,容易产生误判。更稳妥的做法是开启混合检索(Hybrid Search),并设置合理权重,例如语义检索 0.7、全文检索 0.3。
同时启用Rerank 重排序模型,对初步命中的结果进行二次筛选,仅将最相关内容提供给推理模型。
四、针对推理模型的提示词结构优化思路
与传统生成模型不同,DeepSeek-R1 的优势在于其内置的推理机制。在企业知识库场景中,提示词的目标并不是“让模型多说”,而是“约束其推理路径”。
实践中更有效的提示策略是:要求模型先进行内部逻辑梳理,再基于检索内容输出结论,并在存在冲突时遵循明确的优先级规则(如时间顺序或制度等级)。这种方式可以显著降低模型在制度类问题上的随意发挥。
五、不同业务场景下的 RAG 参数差异化配置
企业内部并不存在“一套参数通吃所有场景”的配置方案。不同知识资产,对准确性与发散性的要求存在显著差异。
- HR / 制度类:提高相似度阈值,限制 Top-K 数量,优先保证答案一致性。
- 研发 / 产品类:适当降低阈值,扩大上下文窗口,允许跨文档关联。
这种差异化配置,往往比单纯更换模型更能提升实际使用体验。
六、FAQ:企业级 R1 落地常见问题汇总
Q1:推理时间过长导致前端超时如何解决?
A:建议启用流式输出,并适当提高接口超时时间,让用户在等待过程中持续获得反馈。
Q2:如何防止越权访问敏感文档?
A:权限控制必须在数据集层完成,而不是依赖提示词约束。物理隔离永远优先于语言约束。
Q3:满血 R1 的长期成本是否可控?
A:在主流服务商定价体系下,其单位处理成本处于“个位数人民币级别”,远低于人工分析成本。
七、 结语:在 2026 建立您的内容护城河
不要再纠结 DeepSeek 官网是否拥堵,也不要因为万知的入口消失而止步不前。真正的 AI 玩家已经开始利用 R1 的满血内核构建私有的企业知识引擎。数据是您的资产,逻辑是您的武器。将两者结合,才能在 AI 动荡期建立起真正的竞争壁垒。
站长推荐阅读:
 浙公网安备33010202004812号
浙公网安备33010202004812号