CosyVoice 2.0 是什么
CosyVoice 2.0 是由阿里巴巴通义实验室(Tongyi Lab)旗下的 FunAudioLLM 团队开发的中文语音生成大模型。该模型在 2024 年 12 月正式发布,旨在提供高质量、自然流畅的中文语音合成服务,广泛应用于语音助手、播音配音、智能客服等场景。
CosyVoice 2.0 是继 CosyVoice 1.0 之后的升级版本,采用了更先进的技术架构和训练方法,进一步提升了语音合成的质量和效率。该模型在多个语音合成任务上取得了显著的性能提升,成为中文语音合成领域的重要里程碑。模型现已上线阿里云百炼。
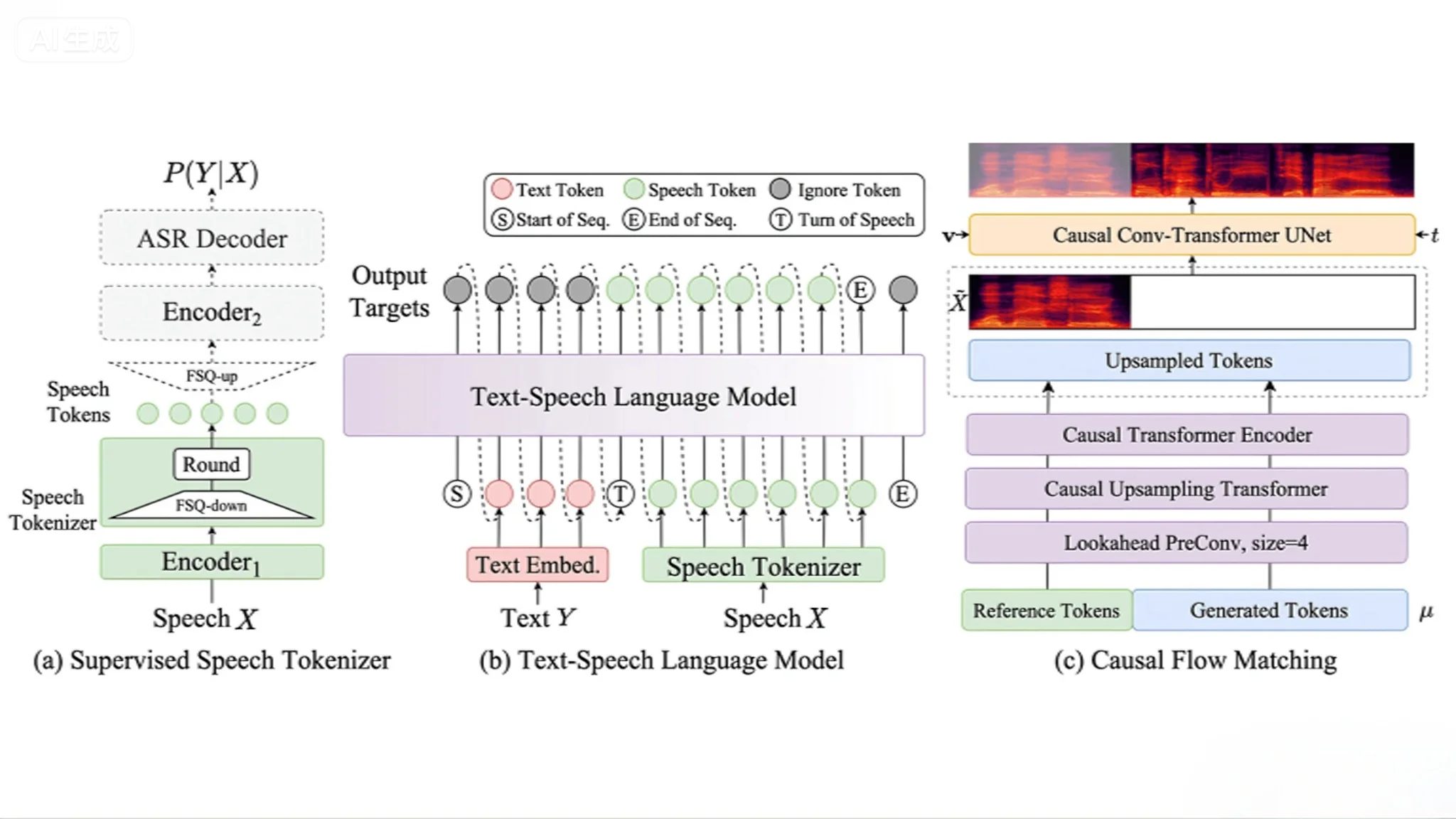
CosyVoice 2.0 的主要功能
- 高质量语音合成:CosyVoice 2.0 能够生成自然、流畅的中文语音,支持多种语气和情感表达,适用于新闻播报、广告配音等场景。该模型采用了先进的声学建模技术,能够更好地捕捉语音的细节和韵律,提高语音合成的自然度和真实感。
- 多语种支持:除了中文,CosyVoice 2.0 还支持多种语言的语音合成,满足全球用户的需求。该模型通过多语言预训练和迁移学习,能够在不同语言之间共享知识,提高语音合成的效率和质量。
- 情感语音合成:该模型能够根据输入的文本内容,生成具有特定情感的语音,如愉快、悲伤、愤怒等,提升用户体验。CosyVoice 2.0 通过情感标签和语音特征的联合建模,能够更准确地捕捉文本中的情感信息,实现情感语音合成。
- 低延迟实时合成:CosyVoice 2.0 支持低延迟的实时语音合成,适用于语音助手、智能客服等需要快速响应的场景。该模型通过优化模型结构和加速推理过程,能够在保证语音质量的同时,降低语音合成的延迟。
- 高可定制性:用户可以根据自身需求,调整语音的语速、音调、音量等参数,实现个性化的语音合成效果。CosyVoice 2.0 提供了丰富的配置选项,用户可以根据具体应用场景,灵活调整语音合成的各项参数。
CosyVoice 2.0 的技术原理
- 基于 Transformer 的模型架构:CosyVoice 2.0 采用了 Transformer 架构,能够更好地捕捉长距离依赖关系,提高语音合成的自然度和流畅性。该架构通过自注意力机制,能够在全局范围内建模语音的上下文信息,实现高质量的语音合成。
- 多任务学习:通过多任务学习,CosyVoice 2.0 能够同时学习语音合成和情感识别,提高模型的综合性能。该模型通过共享参数和任务特征,能够在多个任务之间共享知识,提高模型的泛化能力。
- 自监督学习:利用大量未标注的语音数据进行自监督学习,提升模型的泛化能力和鲁棒性。CosyVoice 2.0 通过自监督预训练,能够在没有人工标注数据的情况下,学习到语音的潜在表示,提高模型的性能。
- 知识蒸馏:通过知识蒸馏技术,将大型模型的知识迁移到小型模型,提高模型的推理速度和效率。CosyVoice 2.0 通过教师-学生模型的训练方式,能够在保持模型性能的同时,减少模型的计算量和存储需求。
- 端到端训练:CosyVoice 2.0 采用端到端的训练方式,减少了传统语音合成系统中多个模块之间的误差积累,提高了语音合成的质量。该模型通过联合优化声学模型和语音合成模块,实现了从文本到语音的直接映射。
CosyVoice 2.0 的项目地址
- 项目官网:https://funaudiollm.github.io/cosyvoice2/
- GitHub仓库:https://github.com/FunAudioLLM/CosyVoice
- 技术论文:https://funaudiollm.github.io/pdf/CosyVoice_2.pdf
- CosyVoice 3技术论文:https://arxiv.org/pdf/2505.17589
和其他 AI 模型相比,CosyVoice 2.0 有哪些优势?
与其他同类模型相比,CosyVoice 2.0 在多个方面表现出色,以下是与 FastSpeech 2(v2.1)和 Tacotron 2(v1.0)进行的详细对比:
1. 架构与技术创新
- CosyVoice 2.0:采用了预训练的文本基座大模型(Qwen2.5-0.5B)作为文本编码器,结合有限标量量化(FSQ)技术,提升了语音 token 的码本利用率,实现了更自然的语音合成。
- FastSpeech 2.1:基于 Transformer 架构,采用了非自回归的生成方式,提升了合成速度,但在情感表达和音色一致性方面相对较弱。
- Tacotron 2 v1.0:结合了 LSTM 和 WaveNet,生成高质量的语音,但在实时性和多语言支持方面存在一定限制。
2. 多语言与情感控制
- CosyVoice 2.0:支持中文(普通话、粤语、东北话)、英文(美式、英式)、韩语、日语等多种语言,且在跨语言和混合语言的语音克隆方面表现优异。
- FastSpeech 2.1:主要支持英文,其他语言的支持有限,且情感控制能力较弱。
- Tacotron 2 v1.0:支持英文,但在多语言和情感控制方面的表现不如 CosyVoice 2.0。
3. 性能与延迟
- CosyVoice 2.0:支持双向流式语音合成,首包合成延迟低至 150 毫秒,发音错误率减少了 30% 到 50%,在基准测试中达到了最低字符错误率。
- FastSpeech 2.1:合成速度较快,但在低延迟和发音准确性方面不如 CosyVoice 2.0。
- Tacotron 2 v1.0:生成速度较慢,且在实时性和发音准确性方面存在一定差距。
4. 应用场景
- CosyVoice 2.0:广泛应用于智能客服、语音助手、有声阅读、广告配音、教育培训等场景,特别适合需要高质量语音输出的应用。
- FastSpeech 2.1:适用于需要快速语音生成的场景,但在音质和情感表达方面有所妥协。
- Tacotron 2 v1.0:适用于对语音质量要求较高的场景,但在实时性和多语言支持方面存在限制。
综上所述,CosyVoice 2.0 在架构创新、多语言支持、情感控制、性能和应用场景等方面均表现出色,是当前语音合成领域的领先模型之一。
CosyVoice 2.0 的应用场景
- 智能语音助手:为智能设备提供自然流畅的语音交互体验。用户可以通过语音与设备进行互动,获取信息、控制设备等,提高使用效率和便利性。
- 智能客服:提升客户服务的效率和质量,提供更人性化的服务。通过语音识别和合成技术,智能客服系统能够自动识别用户问题并提供相应的语音回复,减少人工干预,提高服务效率。
- 有声阅读:将文本内容转化为语音,方便用户随时随地收听。用户可以通过语音合成技术,将电子书、新闻、文章等内容转化为语音,方便在开车、运动等场景下收听。
- 语音导航:为导航系统提供清晰、准确的语音指引。通过语音合成技术,导航系统能够实时提供语音指引,帮助用户更好地规划路线,避免走错路。
- 语音翻译:实现实时语音翻译,促进跨语言交流。用户可以通过语音输入,系统自动识别并翻译成目标语言,实现实时语音翻译,促进跨语言交流。
- 教育培训:为在线教育平台提供语音讲解和互动功能。通过语音合成技术,在线教育平台能够提供语音讲解和互动功能,提高学习效果和用户体验。
- 智能硬件:为智能硬件设备提供语音交互功能。通过语音合成技术,智能硬件设备能够实现语音控制和反馈,提高用户体验和设备智能化水平。
- 广播电视:为广播电视台提供语音播报和配音服务。通过语音合成技术,广播电视台能够实现自动化的语音播报和配音,提高工作效率和节目质量。
常见问题 FAQ
- CosyVoice 2.0 是否支持多语言语音合成?
答:是的,CosyVoice 2.0 支持多种语言的语音合成,满足全球用户的需求。该模型通过多语言预训练和迁移学习,能够在不同语言之间共享知识,提高语音合成的效率和质量。 - 如何使用 CosyVoice 2.0 进行语音合成?
答:用户可以通过 GitHub 仓库中的代码,或者在阿里云百炼平台上使用 CosyVoice 2.0 进行语音合成。用户可以根据自身需求,选择合适的使用方式,进行语音合成。 - CosyVoice 2.0 是否支持情感语音合成?
答:是的,CosyVoice 2.0 支持根据输入的文本内容,生成具有特定情感的语音。用户可以选择不同的情感模式,如愉快、悲伤、愤怒、惊讶等,模型会自动调整语音的音调、语速和韵律,使生成的语音更符合情感表达需求。 - CosyVoice 2.0 的模型大小是多少?
答:CosyVoice 2.0 提供多个版本,模型大小从数百 MB 到数 GB 不等。小型模型适合嵌入式设备和移动端使用,大型模型适合高质量语音合成和云端服务,用户可以根据应用场景选择合适的版本。 - CosyVoice 2.0 是否支持实时语音合成?
答:是的,CosyVoice 2.0 支持低延迟的实时语音合成。通过优化模型结构和推理算法,能够在毫秒级延迟内生成语音,非常适合语音助手、客服系统和实时翻译场景。 - CosyVoice 2.0 的硬件要求高吗?
答:CosyVoice 2.0 在不同版本下的硬件需求不同。大型模型需要 GPU 或高性能服务器来运行,而小型模型在普通 PC 或移动设备上也能高效运行。用户可根据自身环境选择合适的版本。 - CosyVoice 2.0 能否进行个性化语音定制?
答:可以,CosyVoice 2.0 支持个性化语音定制。用户可以上传自己的语音样本,模型会根据样本特征生成相似声音,适用于品牌配音、个人助手和虚拟形象等场景。 - CosyVoice 2.0 是否开源?
答:是的,CosyVoice 2.0 在 GitHub 和 Hugging Face 平台均提供开源版本,开发者可以自由使用、研究和二次开发。开源版本提供了详细的文档、示例和 API,方便快速上手。 - CosyVoice 2.0 如何保证语音质量和自然度?
答:CosyVoice 2.0 采用先进的 Transformer 架构、多任务学习和自监督预训练技术,能够充分捕捉语音的音高、音色、韵律和节奏,从而生成高度自然的语音效果。此外,模型经过大量高质量语音数据训练,确保生成语音贴近真实人声。 - CosyVoice 2.0 可以应用在哪些商业场景?
答:CosyVoice 2.0 广泛应用于智能客服、语音助手、广告配音、有声阅读、导航系统、教育培训、广播电视及智能硬件等场景。其高自然度、情感表达能力和低延迟特性,使其在各类商业应用中表现出色。
© 版权声明
本站文章版权归AI工具箱所有,未经允许禁止任何形式的转载。
相关文章
暂无评论...
AI工具箱导航官网汇集了来自国内外的上千款AI工具。每日更新和添加最新的AI工具。此外还收录了常用的AI学习开发网站、框架和模型。帮助你轻松跟上人工智能的步伐,实现任务自动化,提升工作效率!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 浙公网安备33010202004812号
浙公网安备33010202004812号