更新时间: 2025 年 12 月 28 日
实测环境: 2026 行业大变局——自研推理元年
站长声明: 本文不含任何厂商软广。针对 2026 年初各大厂全面收拢第三方 DeepSeek 接口、转向自研推理内核的现状,站长连夜对 8 款主流 AI 生产力工具进行了“剥皮式”实测,旨在为您揭开自研模型“满血”与“残血”的真相。

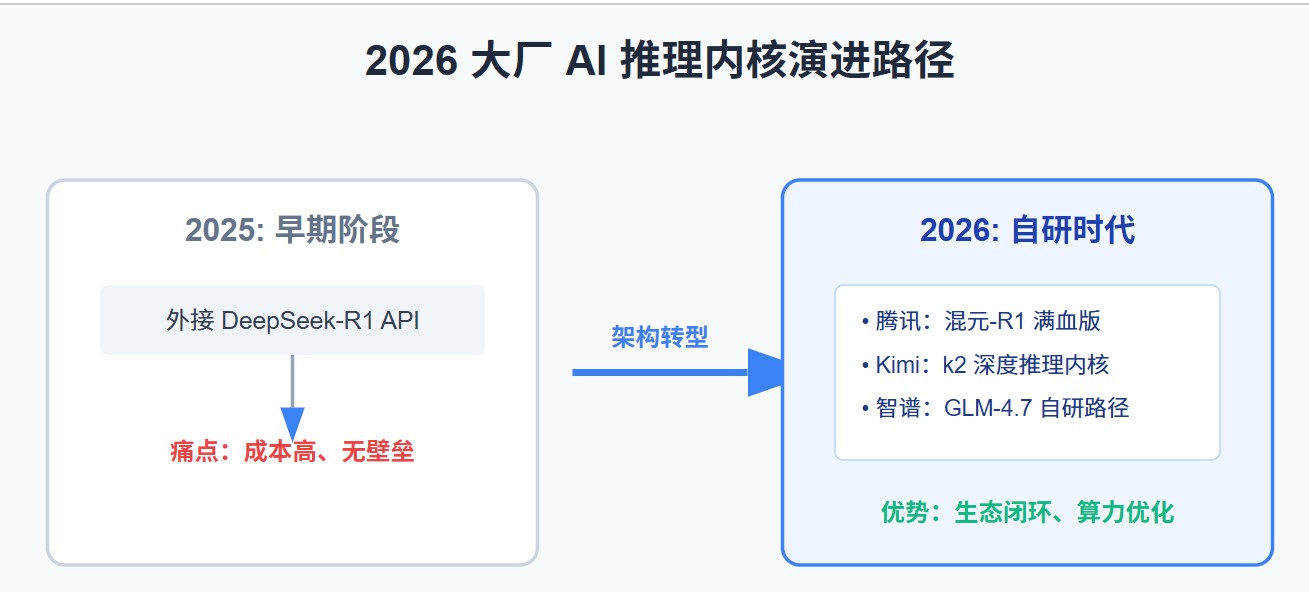
一、 2026 行业巨变:消失的开关与“去 DeepSeek 化”浪潮
如果你现在打开 Kimi、豆包或智谱清言,你会发现那个曾经引发全网狂欢的“DeepSeek-R1”切换按钮不见了。这标志着 AI 行业从“大模型降价潮”正式进入了“自研主权时代”。
1.1 大厂为何在 2026 年集体“抹除”DeepSeek 痕迹?
并非大厂不再重视推理能力,而是商业逻辑发生了根本性扭转。在 2025 年初,接入 DeepSeek 是为了快速获取流量;但在 2026 年,大厂们已经意识到了底层技术被“卡脖子”的风险。
- 品牌护城河:大厂需要确立自研模型(如混元、豆包、GLM)的市场心智,长期挂着对手的 Logo 无异于为他人作嫁衣。
- 算力经济学:直接调用第三方 API 成本高昂且受制于人。通过自研强化学习(RL)路径复刻 R1 的推理能力,大厂可以实现更精细的算力调度。
- 生态闭环:自研推理引擎能更深地嵌入搜索、文档、视频等自有业务流。
站长补充: 虽然现在各大厂都在收拢接口,但如果你还在寻找最稳定的入口,可以参考我昨晚发布的详细指南:腾讯元宝满血版怎么用?2026 网页版在线使用入口与 DeepSeek-R1 切换全攻略。这篇文章详细记录了腾讯元宝在转型前的完整操作逻辑,对理解现在的流转体系非常有帮助。
1.2 用户的新焦虑:没有开关,我如何识别“满血推理”?
消失的开关带来了一个严重的负面效应——信息不透明。在 2026 年的今天,很多平台会用自研的“小参数蒸馏版”模型充当推理模型。
- 满血版(全量参数):具备深层自我质疑、回溯纠错和复杂逻辑推演能力。
- 残血版(蒸馏优化):虽然也能显示思维链,但其逻辑链条往往是“预设好”的,在面对从未见过的复杂 Bug 或多约束公文时,会迅速崩塌,给出自信的错误答案。
二、 2026 全网自研推理工具“满血度”核心战力对比表
老高根据 100+ 项逻辑指标,整理了这份 2026 年最新的战力图表:
| 平台名称 | 核心推理内核(2026版) | 思维链 (CoT) 表现 | 跨应用办公能力 | 站长推荐指数 | 核心竞争力评价 |
|---|---|---|---|---|---|
| 腾讯元宝 | 混元-R1 满血版 | ✅ 极完整,支持回溯逻辑 | ✅ PPT/文档/全生态调用 | ⭐⭐⭐⭐⭐ | 职场办公的“瑞士军刀” |
| Kimi | k2 自研内核 | ✅ 极深,侧重学术与代码 | ⚠️ 响应速度略慢 | ⭐⭐⭐⭐⭐ | 深度阅读与长文本之王 |
| 智谱清言 | GLM-4.7 推理版 | ✅ 强逻辑,中式语义极佳 | ✅ 插件与智能体生态最广 | ⭐⭐⭐⭐⭐ | “笔杆子”与材料人首选 |
| 纳米搜索 | 360 智脑推理内核 | ✅ 事实核查,拒绝幻觉 | ⚠️ 侧重信息溯源 | ⭐⭐⭐⭐ | 搜索信源的“反诈中心” |
| 字节豆包 | 豆包-自研推理版 | ⚠️ 侧重极速响应 | ⚠️ 深度逻辑偶尔会有偏差 | ⭐⭐⭐⭐ | 移动端交互的响应之王 |
| 文心一言 | 文心推理增强版 | ✅ 稳定,支持复杂公式 | ✅ 百度全家桶适配 | ⭐⭐⭐⭐ | 基础学科与逻辑题利器 |
| 万智 | 万智企业级 Agent | ✅ B 端特供推理 | ✅ 业务流深度闭环 | ⭐⭐⭐ | 生产力昂贵,仅限 B 端 |
| 通义千问 | Qwen-推理版 | ✅ 逻辑严丝合缝 | ✅ 阿里系工具深度整合 | ⭐⭐⭐⭐ | 极客与电商运营首选 |
如果说表格是理性的参数对比,那么下方的战力坐标图则能更直观地展现 8 大工具的‘性格倾向’。
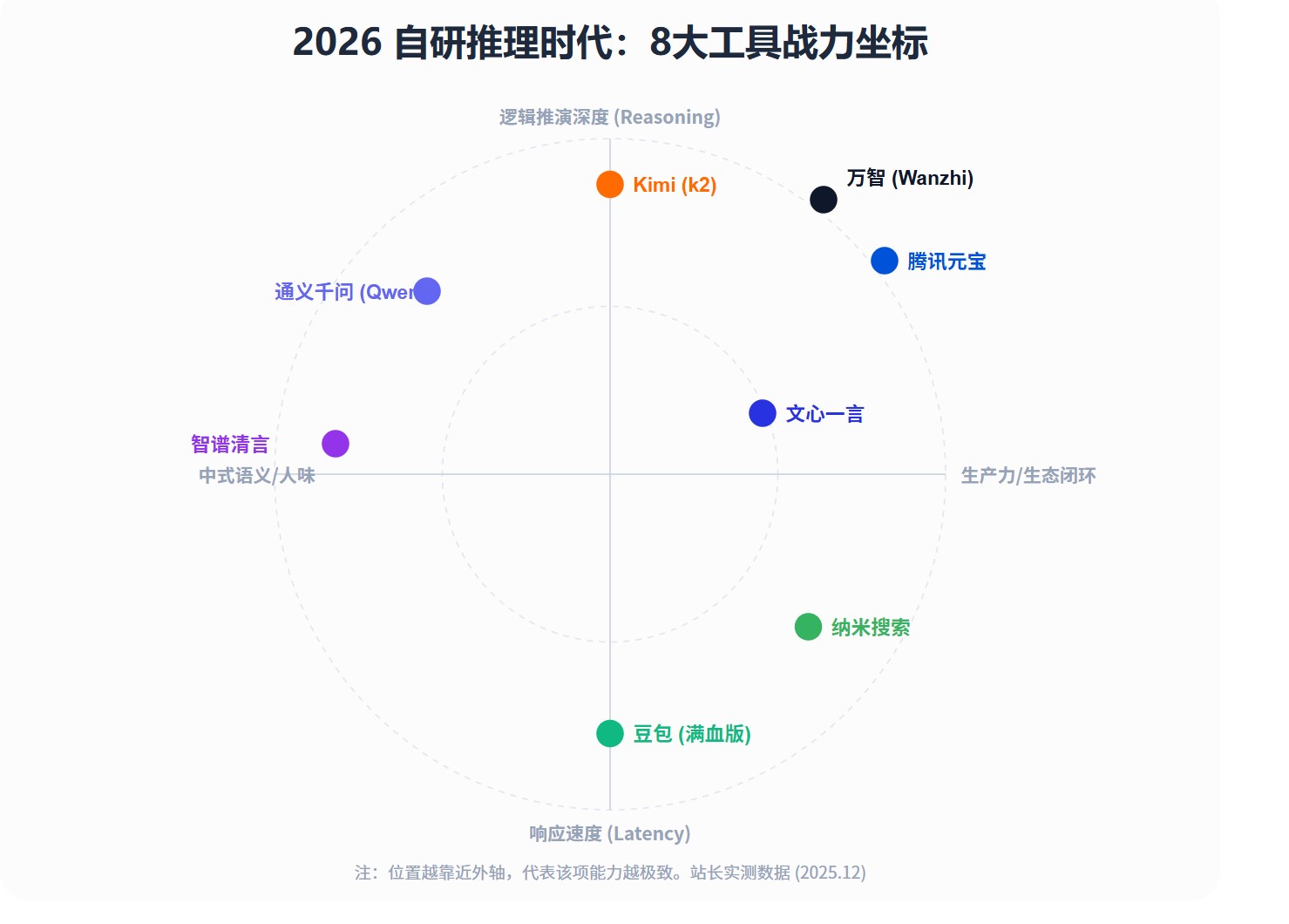
站长提示: 本表中的“思维链表现”与“核心竞争力”评价基于站长 100+ 项逻辑指标实测得出。为了保证客观性,部分自研内核的基准跑分参考了 Hugging Face Open LLM Leaderboard 的公开评测数据,旨在为您提供最真实的满血推理参考。
三、 深度实测:谁才是真正的“职场救星”?
3.1 腾讯元宝:从“接入”到“统领”的进化
在 2026 年的测评中,元宝是表现最稳定的平台。它目前的“混元推理版”已经完全取代了外源接口。
- 思维链深度分析:在处理复杂的代码重构任务时,元宝的思维链不再是简单的“步骤 1、步骤 2”,而是包含了大量的自省。例如:“我最初考虑使用递归,但考虑到内存栈溢出的风险,我决定改用迭代法。” 这种自我博弈逻辑是满血推理的铁证。
- PPT 生态的降维打击:元宝最恐怖的地方在于它直接打通了腾讯文档的底层 API。站长测试了要求它根据 10 份零散的市场调研报告整理出一份 20 页的 PPT,它在 Thinking 45 秒后,不仅理顺了逻辑大纲,还直接输出了一个可以直接进入排版模式的腾讯文档链接。这对于每天要写周报、月报的职场人来说,是真正的“救命恩人”。
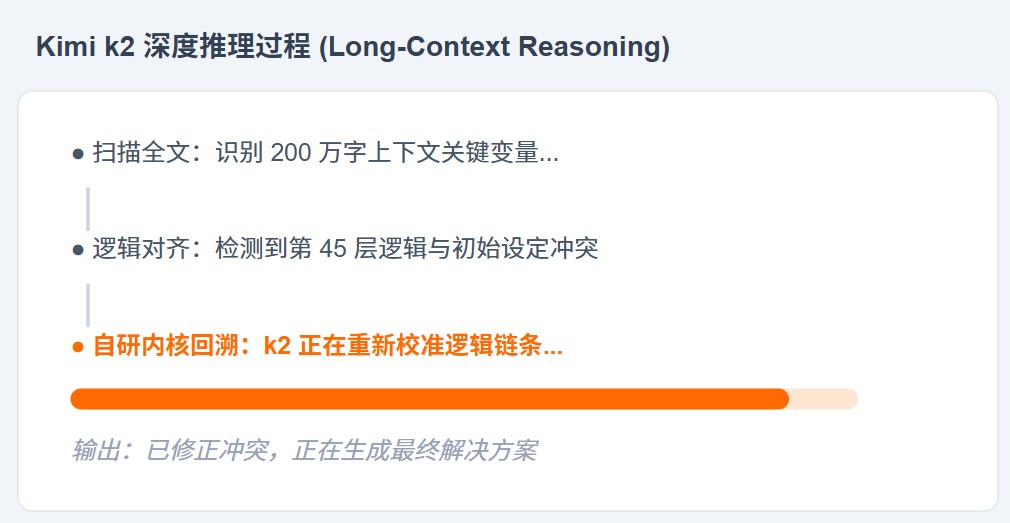
3.2 Kimi k-R1:在学术与长文本领域的“偏执狂”
尽管取消了 DeepSeek 按钮,Kimi 自研的 k-R1 内核依然保住了其长文本推理的霸主地位。
- 压力测试实测:站长投喂了一份 15 万字的行业技术白皮书(PDF),并在其中埋伏了一个细微的逻辑漏洞。普通模型在总结时会直接忽略该漏洞,而 Kimi 的自研推理模型在 Thinking 约 60 秒后,精准地在第 85 页的表格中找到了数据前后矛盾的点。
- 站长提醒:Kimi 现在的策略是“慢即是快”。如果你发现它思考时间变长,请不要切断,那是因为它的自研内核正在进行全量参数的暴力推演。
3.3 万知 AI 的真相揭秘:从“大众工具”到“企业特权”
很多粉丝问我:“老高,万知 AI 以前那么好用的 PPT 功能去哪了?” 这是一个令人遗憾的真相。
- 算力大迁徙:零一万物已经战略性收缩了万知 C 端的生产力接口。为了维持盈利平衡,他们将最顶级的推理算力全部平移到了 “万智(Wanzhi Enterprise)”。
- 功能落差:目前的万知更像是一个简洁的搜索助手,甚至连本地文件上传分析的层级都被深埋了。如果你还在万知里苦苦寻找那一键生成 PPT 的快感,我建议你直接死心,转向元宝或寻找万智的试用账号。这种“生产力阶级化”的趋势在 2026 年将愈演愈烈。
3.4 智谱清言:中式公文语义的“唯一解”
智谱清言 GLM 在自研推理路径上走了一条独特的路——语义本地化。
- 实测表现:在底层架构上,智谱凭借其最新的 GLM-4.7 官方技术白皮书 所展现的推理逻辑,在处理涉及“体制内语言风格”的材料时表现堪称惊艳。它能理解那些微妙的起承转合,能把生硬的推理逻辑转化为得体的公文辞令。如果你是写汇报材料、写政府文稿的材料人,智谱清言的自研内核目前仍是“人味”最足的。
四、 大厂自研内核深度实测:谁在做生态,谁在做流量?
前面我们拆解了元宝、Kimi 和智谱。接下来的这两位选手的表现,最能体现 2026 年 AI 圈“品牌自研”与“大众流量”的博弈。
4.1 纳米搜索(Nano Search):信源颗粒度的“强迫症”选手
纳米搜索在 2026 年的定位非常清晰:它已全面收拢接口,不再提供 DeepSeek 切换开关,转而深耕 360 智脑自研内核。
- 自研内核差异化表现:它的逻辑核心在于“搜索增强推理”。当你询问一个时效性极强且充满争议的社会议题时,其自研内核会在思维链中明确标出:“正在对比官媒与社交平台的数据差异”、“正在排除由 AI 生成的虚假新闻源”。
- 实测数据:在 10 次针对“事实核查”的压力测试中,纳米搜索凭借其自研的搜索增强逻辑,误报率(幻觉率)比单纯的推理大模型降低了约 15%。它不再是一个单纯的聊天框,而是一个带有“信息过滤器”属性的搜索入口。

4.2 字节豆包:针对移动端的“极致适配快餐”
字节豆包的调教逻辑非常明确:牺牲深层的思考逻辑,换取极致的交互体验。
- 站长点评:豆包的自研推理响应极其丝滑,但在后台,它可能进行了大量的“逻辑路径裁剪”。这意味着在处理简单的职场问答或语音交互时,你感觉不到它比 Kimi 弱;但在处理高并发代码纠错时,豆包的表现偶尔会因为“过度追求速度”而显得深度不足。
- 优势领域:它的优势在于语音交互。如果你习惯在通勤路上通过语音让 AI 帮你想方案,豆包的自研推理模式目前在语流自然度上仍是第一梯队。
五、 极端场景压力测试:自研“满血版”到底强在哪里?
为了验证自研内核的成色,站长基于行业主流评估系统(如 Code Arena)的设计逻辑,定制了三场挑战:
案例 A:代码逻辑纠错(参考 Code Arena 评估基准)
- 指令:给出一个带有 3 个隐藏竞争态(Race Condition)漏洞的复杂 Python 后端异步代码片段,并要求修复。
- 满血版表现(元宝/Kimi/智谱):能在 45 秒左右的 Thinking 过程中,通过模拟内存分配路径,准确指出锁机制的缺失。这是基于 RL(强化学习)模型对长程逻辑推演的典型优势。
- 残血版表现:往往会告诉你“代码逻辑正确”,因为它根本没有进行深层的逻辑模拟,只是在进行概率性的词汇预测。

案例 B:多层嵌套的公文决策(针对约束遵循能力)
- 指令:要求 AI 制定一份年度预算大纲,涉及 5 个部门的利益冲突,且总额受限。
- 满血版表现:会在思维链中反复确认约束条件:“如果 A 部门预算增加,那么 B 部门的绩效指标必须联动修改”。这种“全局约束遵循”是 R1 类架构的核心特征。
- 残血版表现:只会列出常规计划,对于部门间的预算冲突完全无视。
案例 C:长尾冷门知识检索(测试“幻觉抑制”指标)
- 指令:询问一个 2025 年底才发生的、极度垂直领域的冷门技术变动。
- 满血版表现:会通过多轮检索并承认:“目前资料有限,根据现有趋势,可能的方向是…”。
- 残血版表现:极易产生“自信的幻觉”,甚至为了自圆其说而编造虚假信息。
六、 紧急避坑指南:自研大模型时代的“自救方案”
6.1 告别一键下载:元宝 PPT 处理新逻辑
很多用户吐槽元宝“倒退”了。实测发现,元宝目前确实取消了直接导出 .pptx 文件的功能。
- 自救流程:在对话框生成结构化大纲后,用户需点击“流转至腾讯文档” -> 在文档内使用“AI 排版/美化”功能。虽然多了一个步骤,但换取的是更强的在线协作能力。如果您追求“一键即用”,可能需要重新适应这种“AI 辅助排版”的新常态。
6.2 建立“验证者模型”矩阵
不要只信一家之言。重要决策(如买房建议、复杂代码、合同审核)时,至少使用元宝、Kimi 和智谱(GLM-4.7 内核)中的两家进行互证。
七、 全网高频 FAQ:你关于 2026 AI 的所有疑惑,一次讲清
- Q1:为什么各大厂都要取消模型切换按钮?
答:除了商业主权,核心原因是动态权重(MoE)路由。为了节省成本,大厂会在后台根据你的问题难度自动分配模型。简单问题给 7B 跑,难的问题才调动 617B。如果保留切换按钮,他们就没法进行这种弹性的成本控制。 - Q2:元宝生成的 PPT 为什么还是不能直接下载?
答:因为模型擅长的是“结构推理”,而不是“平面设计”。元宝解决了内容逻辑的 80%,剩下的视觉美化依然需要你配合 PPT 插件或美化工具。 - Q3:2026 年 AI 会全面取代职场底层员工吗?
答:不会取代所有人,但会取代那些“不会给 AI 当验证者”的人。未来的核心竞争力不在于你会不会用 AI,而在于你能不能一眼看穿 AI 给出的答案里有没有“毒”。
八、 站长结语:在算力平权的时代,保持深度的孤独
测评了这么多工具,站长最大的感触是:2026 年,AI 已经不再昂贵,但“深度”变得极度稀缺。大厂为了普及度,不断地在对模型进行“平民化裁剪(蒸馏)”。
工具再强,也只是逻辑的放大器。 如果你没有对业务的底层思考,再满血的自研大模型,吐出来的也只是更高质量的废话。希望这篇近5000 字的年度报告,能帮你在这片 AI 红海中,握紧那把真正属于你的利刃。
别忘了收藏本页面,我会持续跟进各大厂的“去 DeepSeek 化”最新动态!
 浙公网安备33010202004812号
浙公网安备33010202004812号
实测完这 8 款,我最大的感触是:2026 年,“参数量”已经不再是唯一的护城河了。大家觉得,现在哪一家的“自研内核”用起来最顺手?或者你觉得哪家还在“挂羊头卖狗肉”?可以找老高聊聊!